9 Big five personality 1
9.1 Intended Learning Outcomes
By the end of this chapter you should be able to:
- Explain what the Big Five model of personality is
- Create your own R Markdown documents with code chunks
- Explain the concept of forward and reverse coding
9.2 Psych 1B
Welcome back to Psych 1B! Whilst much of the data skills work this semester will seem very familiar, now that you've got the basics of R, there will be a few minor changes to our approach to help scaffold you towards becoming an independent learner which will be really important at Level 2.
First, you'll notice that we have reduced the number of walkthrough videos. Rather than having walkthroughs for every chapter, they're limited to a couple of chapters that introduce a lot of new coding concepts. If you'd like additional help working through the chapters, remember that you can attend office hours or GTA sessions. You don't have to have a specific question, some students use the GTA times to complete their data skills work so if they come across a problem, they're already in a place where support is available.
Second, in Psych 1A we provided you with the Markdown stub files, this semester you'll create your own (and we'll recap how to do that in this chapter).
Third, there are still three data skills homeworks but they are all now summative and worth 5% of your grade compared to Psych 1A where the first one was formative. Check the Assessment Information Sheet on Moodle for more information.
And finally, in Psych 1A we strongly recommended that you should use the server rather install R on your own machine. Now that you're more familiar with the basics, if you'd like to install R and RStudio on your machine you can find instructions for how to do so in Appendix A and if you run into any problems, the GTAs can help you. The advantages to installing R on your machine are a) you're not reliant on the server (which does occasionally crash) b) you don't need to be connected to the internet to use R and c) it makes it much easier to check your homework files before you submit them. That all said, if you're comfortable using the server it's absolutely fine to keep doing so.
9.3 Activity 1: Personality traits
For the next set of chapters we're going to use data from the most popular model of personality, the Big Five.
- First, take part in this online version of the Big-5. It only takes a few minutes to complete and it used the items from Soto and John (2017) which a short-form version of the Big Five Inventory 2 (BFI-2).
- Second, read the textbook chapter on personality trait theorists.
- Finally, answer the following questions. Please note that your responses will not save in the browser - if you want to save them, make a note of them somewhere.
- The trait 'Agreeableness' in the Big Five personality model refers to:
- In the context of the Big Five Personality model, which trait might be associated with a person who is diligent, efficient, and follows a schedule?
- Individuals who are often nervous, insecure, and easily upset, are considered to have high according to the Big Five Personality Model.
- In the Big Five Personality Model, people who are outgoing, sociable, and assertive score high on the trait known as
- Which of these traits in the Big Five Personality model is most closely associated with creativity and a preference for novelty?
The correct answer is "The tendency to be compassionate, cooperative, and warm towards others". Agreeableness as a personality trait characterizes individuals who are friendly, compassionate, and like working with others. They tend to be more cooperative while interacting with others.
The correct answer is "Conscientiousness". This trait is associated with people who are organized, responsible, and prefer planned rather than spontaneous behavior. High conscientiousness means a person is disciplined, efficient, and diligent.
Neuroticism is a personality trait in the Big Five Model. High neuroticism often means a person is likely to experience feelings such as anxiety, anger, or depression. These individuals are more likely to interpret ordinary situations as threatening and minor frustrations as hopelessly difficult.
Extraversion characterizes individuals who are outgoing, sociable, and often possess high group visibility. They like to talk, assert themselves, and draw attention to themselves.
The correct answer is "Openness to Experience". Individuals with high openness are often very creative, curious about their surroundings, and more aware of their feelings. They tend to think and act in individualistic and non-conforming ways and are likely to have a broad range of interests.
9.4 Activity 2: New project
- Log in to the to R sever and make a new project for the Big-5 chapters (this week and next week).
- If you've decided to install R on your machine, create a new project by clicking
File -> New Project. The rest of the process is the same as on the server.
9.5 Activity 3: Data files
Once you've done all this, it's time to download the files we need and then upload them to the server.
- First, download the Big 5 data zip file to your computer and make sure you know which folder you saved it in.
- Then, on the server in the Files tab (bottom right), click
Upload > Choose filethen navigate to the folder on your computer where the zip file is saved, select it, clickOpen, thenOK. - If you're working on your own machine, you will need to unzip the files before you can use them. There is a short walkthrough via YouTube for how to do this on Windows and Mac. You need to unzip the files into your project folder. If you need help with this, come to office hours or a GTA session.
The zip file contains three files:
-
big5_data.csvis a data file that contains each participant's response to each question on the full version of the Big Five Inventory-2. There are 60 items in total, and there are 12 items for each of the five personality traits. Each item has a response from 1 (disagree strongly) to 5 (agree strongly). -
code_book.csvis a data file that lists the name of each question as it was stored in the questionnaire survey software (e.g.,Q4_1), which trait the item refers to (e.g.,extraversion), and whether it is aforwardor `reversed`` scored item (we'll come back to what this means in a moment). -
scoring.csvis a data file that indicates what score each participant response should get depending on whether it is a forward or reversed item.
9.6 Activity 4: New R Markdown
As noted, this semester we're not going to provide stub files, instead you need to create your own RMarkdown files. If you'd like a full refresher on exactly how to do this, you can review Chapter 1 but here's the brief version:
- Click
File - New File - R Markdown. - Give the document the title "Big five 1" and put in your GUID as the author.
- Save the file by clicking
File - Save as. It should be saved in your project directory alongside all the data files from Activity 3. - The gif below is from the Intro chapter and shows how to do this with a slightly different file name.
Figure 1.6: Opening a new R Markdown document
Next you need to add text and code chunks.
- Delete everything from line 8 onwards. On line 8, type "## Activity 5" and press enter to move the cursor down to line 9
- Click the code chunk button at the top of your Markdown document (it's a green square with a C and a plus sign) then click
Rto insert a new R code chunk.
- The gif below is from the Intro chapter and shows how to do this with slightly different text.
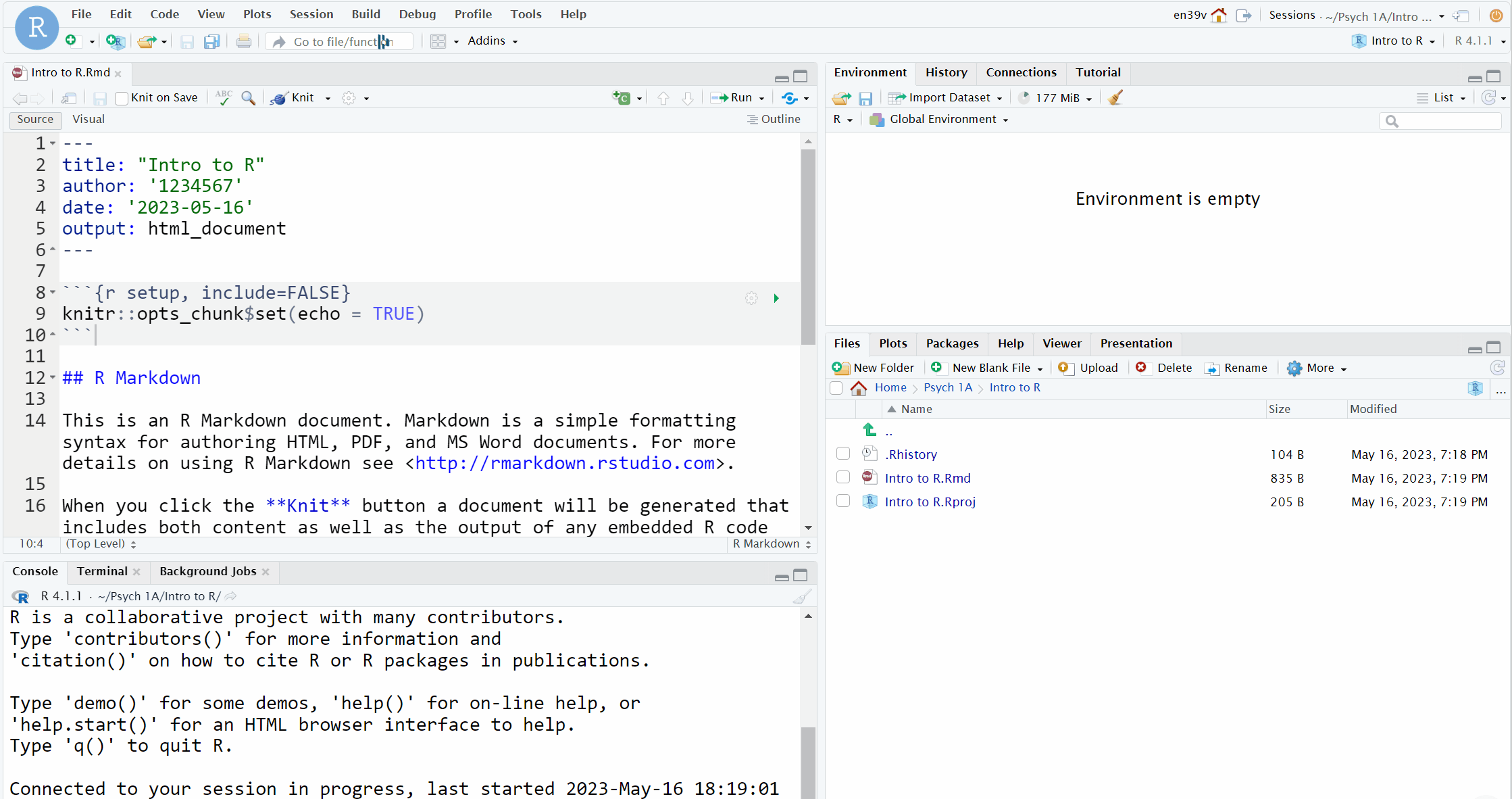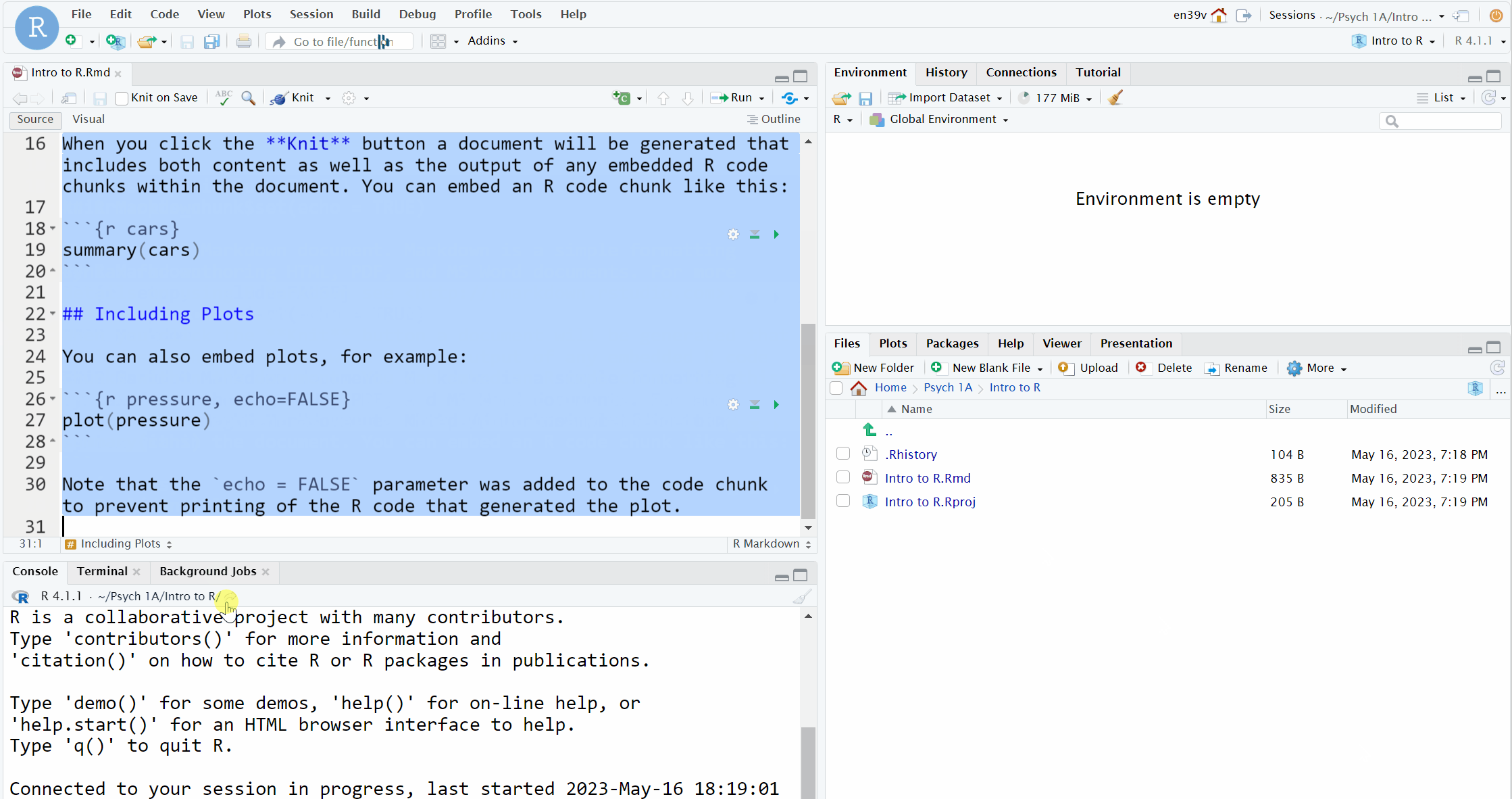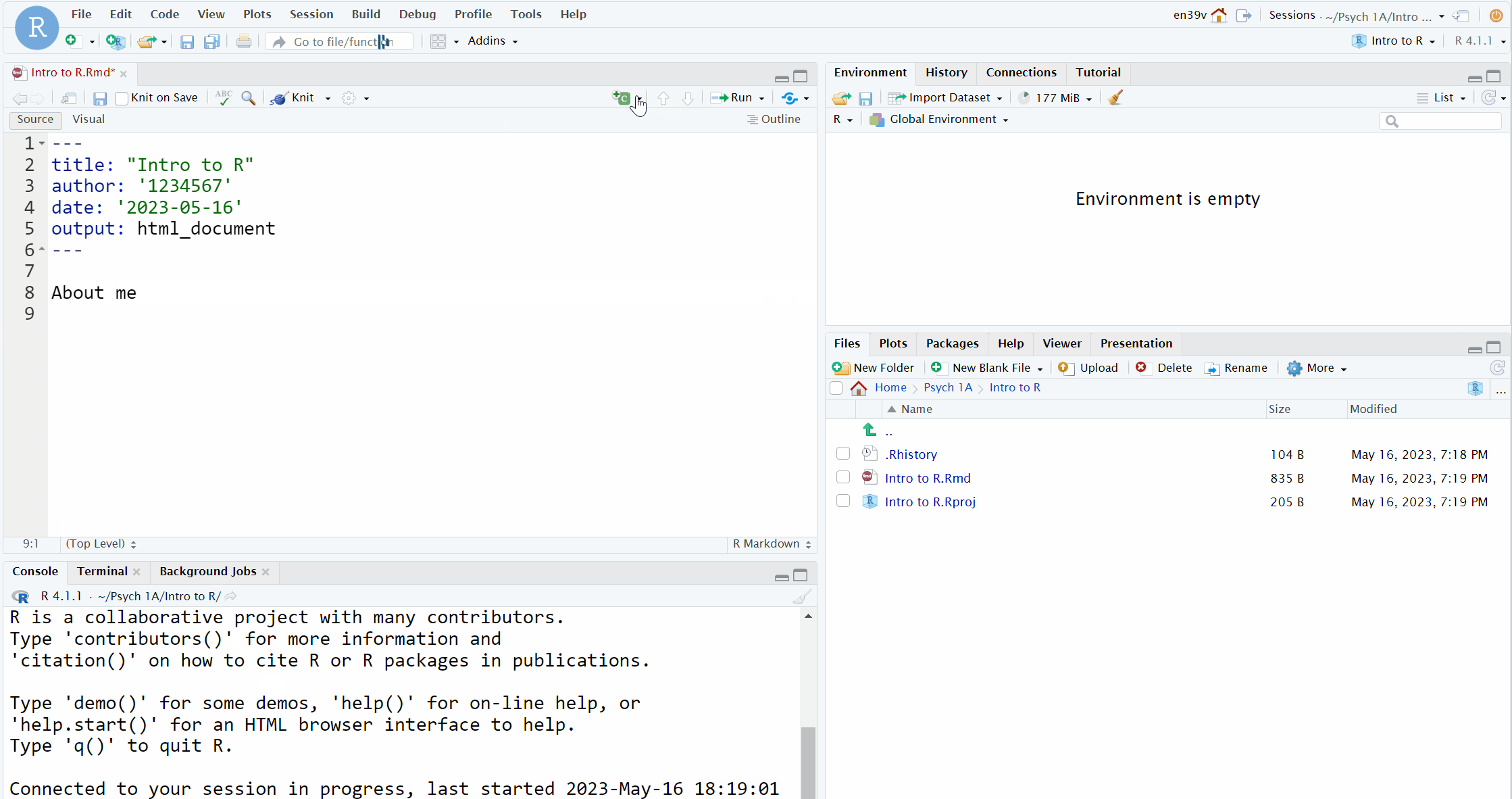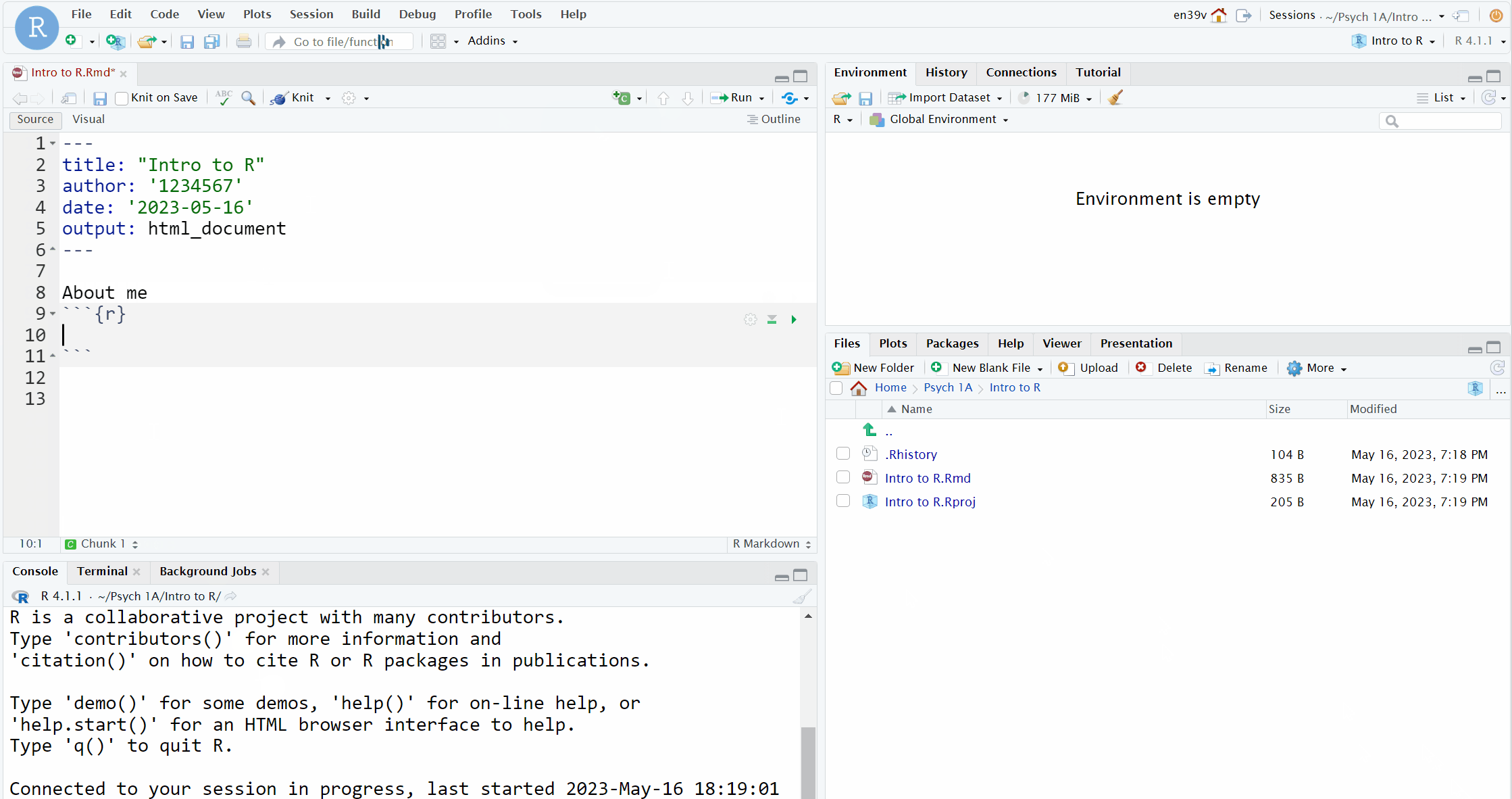
Figure 1.7: Creating a new R chunk
To make your life easier you can also use keyboard shortcuts. The default shortcut for adding a new code chunk is Cmd + Option + I on a Mac or Ctrl + Alt + I on Windows. You should create a new code chunk for each activity or each analysis step (like there was in the stub files from 1A) and make sure there is a description of what the code is doing. This will make it easier to read your Markdown and find where any errors in the code are. Do not put all of your code in one big chunk.
9.7 Activity 5: Loading data
Now we've got everything set up, in the code chunk you just created write and run the code that:
- Loads the
tidyverse. - Uses
read_csv()to loadbig5_data.csvinto an object namedbig5. - Loads
scoring.csvinto an object namedscoring. - Loads
code_book.csvinto a object namedcodebook.
Whilst coding isn't about memorisation and we certainly don't expect you to be able to write more complicated code off by heart, you should be able to do this task from memory. If you can't, it may be that you've been relying too much on the hints and solutions. Remember that it will make things much easier in the long-run not to take shortcuts at the beginning.
library(tidyverse)
big5 <- read_csv("big5_data.csv")
scoring <- read_csv("scoring.csv")
codebook <- read_csv("code_book.csv")r unhide()
9.8 Activity 6: Forward & reverse scoring
Before we go any further, let's explain what we mean by forward and reverse scoring. One of the issues with conducting research using surveys is that if we don't design them carefully, our data may be affected by response bias. One type of response bias is acquiescence bias, which is the finding that people have a tendancy to agree with all statements. To try and minimise the impact of this, many questionnaires will reverse-code some of the questions so that a positive response means agreeing with one question but disagreeing with another.
- Below are five of the Big 5 items that relate to "Agreeableness". Type the number of one of the items where you think agreeing with the item would mean the participant displayed a higher level of agreeableness
- Now type the number of one of the items where you think disagreeing with the item would mean the participant displayed a higher level of agreeableness
| Q_No | Question |
|---|---|
| Q 1 | Is compassionate, has a soft heart |
| Q 2 | Feels little sympathy for others |
| Q 3 | Is respectful, treats others with respect |
| Q 4 | Is polite, courteous to others |
| Q 5 | Starts arguments with others |
For those items where agreeing with the item means higher agreeableness, participants receive a score of 1 if they answer "disagree strongly" and a score of 5 if they answer "agree strongly". This is called forward scoring. For those items where disagreeing with the item means a higher agreeableness score, participants receive a score of 1 if they answer "agree strongly" and 5 if they answer "disagree strongly". This is know as reverse coding.
By combining all three datasets, We can use the information in scoring and codebook to score all responses to the Big 5 and we'll do that in the next chapter. Before we get there though, we need to ensure that we fully understand the data we have and revisit the concept of wide and long-form data.
9.9 Activity 7; Check the data
First, answer these questions about the structure of the datasets and the variables they contain. Remember that R is case-sensitive so you need to type these out exactly.
There's a few ways you could answer these questions - run summary() or str() on each object, click on them in the environment pane, or view the list of variables by clicking on the blue arrow next to the object name.
-
scoringandcodebookhave a variable in common. What is the name of this variable? - What is the name of the variable in
big5that contains the Participant's ID? Remember that is case sensitive. . -
big5is in wide-form, which means that all the information about each participant is contained in a single row, so the more data you have, the wider the dataset will be. How many participants are in this dataset? - How many questions are there in total on the Big 5 questionnaire? You've been given this information in this chapter.
- What is the name of the first variable in
big5that contains the response to a BFI item? - What is the name of the last variable in
big5that contains the response to a BFI item?
- They both have a column named "direction".
- The column is named
ResponseIdwhich has very annoying capital letters but this is the default name that the Qualtrics survey software uses and you'll be using it for the group project so you might as well get used to it! - There are 5065 rows of data which means there are 5605 participants. You could have done this with code (
big5 %>% count()), or by checking the output ofsummary()orstr()but you could also just have looked in the environment pane and seen how many observations there were5605 obs. of 61 variables. - The BFI has 60 items and you were given this information in Activity 3.
- The first items is named
Q4_1. - The last item is named
Q4_60. Again there's a few ways of doing this but runningstr(big5)or clicking the blue arrow next to the object name in the environment are probably the easiest.
9.10 Activity 8: Long-form data
In order to be able to join all the data files together in a way that is helpful, we need to transform the big5 dataset from wide-form to long-form. We've seen long-form data before in the Stroop chapter but as a reminder, in wide-form data you have a single row for each participant whereas in long-form data, you have a row for each observation you have about that participant.
- There are 5605 participants and we have data from 60 questions for each of them. If the data were in long-form, how many rows should there be? (You will need a calculator for this, you can use the console in R)
There are 5605 participants and 60 observations each. In long-form, each participant should have 60 rows of data so 5605*60 = 336300.
In long-form, the big5 dataset would look something like this:
| ResponseId | question_name | answer |
|---|---|---|
| R_3O9fzdsGn9tEeOm | Q4_1 | 5 |
| R_3O9fzdsGn9tEeOm | Q4_2 | 4 |
| R_3O9fzdsGn9tEeOm | Q4_3 | 1 |
| R_3O9fzdsGn9tEeOm | Q4_4 | 1 |
| R_3O9fzdsGn9tEeOm | Q4_5 | 5 |
| R_3O9fzdsGn9tEeOm | Q4_6 | 3 |
| R_3O9fzdsGn9tEeOm | Q4_7 | 5 |
| R_3O9fzdsGn9tEeOm | Q4_8 | 1 |
| R_3O9fzdsGn9tEeOm | Q4_9 | 2 |
| R_3O9fzdsGn9tEeOm | Q4_10 | 4 |
Given that we want to be able to eventually join together big5 with scoring and codebook, we want variables that represent the same data to have the same name.
- What should we name
question_nameso that it matches the same column incodebook? - What should we name
answerso that it matches the same column inscoring?answer?
question_name states which question/item the data refers to (these were previously the column names in the wide-form dataset). codebook also has a column with this information but but it is named item so it would be better decision to call it item so it matches.
Similarly, answer is the response the participant gave to that item. In scoring, this information is in a column named response so again we want them to match.
This is the code that transform the data from wide-form to long-form using the function pivot_longer(). We're going to go through how to do this in the next chapter which you'll also work through in the lab. For now, see if you can figure out what each bit of the code is doing and try and write it out in words.
big5_long <- big5 %>%
pivot_longer(cols = Q4_1:Q4_60,
names_to = "item",
values_to = "response") big5_long <- big5 %>% This line is taking the data frame named
big5and passing it to the next function using the pipe operator%>%. Thebig5_longobject will store the result of the operations that follow.pivot_longer(cols = Q4_1:Q4_60, The
pivot_longerfunction is used to transform the data from "wide" format to "long" format. In this case, the function is applied to the columnsQ4_1throughQ4_60of thebig5data frame. The wide format has a column for each variable (in this case, 60 different itemsQ4_1throughQ4_60), while the long format has a row for each variable-value pair.names_to = "item", The
names_toargument specifies the name of a new column that will be created to store the column names from the original data frame (that is, the names of the itemsQ4_1throughQ4_60). This new column will be named "item".values_to = "response") The
values_toargument specifies the name of a new column that will store the values from the original data frame (that is, the responses to the itemsQ4_1throughQ4_60). This new column will be named "response".
So, in summary, this script is taking the big5 data frame and transforming it from a wide format to a long format, where the original column names are stored in a new column named "item", and their corresponding values are stored in a new column named "response". The transformed data frame is then stored in a new object called big5_long.
9.11 Activity 9: Refresh your memory
Finally, so that your memory is refreshed ahead of Psych 1B, answer the following questions:
- What does the select function in the tidyverse primarily do?
The select function is primarily used to choose and extract specific columns (variables) from a data frame or tibble. It allows you to subset your data by selecting only the columns you are interested in for further analysis, which can be very useful when dealing with large datasets.
- What is the main purpose of the filter function in the tidyverse?
The filter function is used to subset or filter rows from a dataset based on specific conditions or criteria. It allows you to retain only those rows that meet certain criteria, making it easier to focus on the subset of data relevant to your analysis.
- What does the mutate function in the tidyverse primarily do?
The mutate function is used to add new columns (variables) to a data frame or tibble, often by applying some transformation or calculation to existing columns. It allows you to create new variables based on the values of other variables, which is useful for generating additional insights or features in your data.
- How do you load an R package named "cowsay" into your R session?
When a package is already installed on your system, you can use the library() function to load it into your R session. This makes the package's functions and features available for use in your R code. So, if "cowsay" is already installed, you can simply load it into your session with library(cowsay) to start using its functionality.