# wrangling and visualisation functions
library(tidyverse)
# Parameter estimates
library(emmeans)
# Ordinal regression for later
library(ordinal)
# plotting model objects
library(sjPlot)
# Bostyn data for logistic regression
bostyn_data <-read_csv("data/Bostyn_2018.csv") %>%
select(STUDY:DECISION) %>% # just select first four variables
drop_na(DECISION) %>%
mutate(study = factor(STUDY,
levels = c(1, 2),
labels = c("Real", "Hypothetical")),
label = factor(DECISION,
levels = c(0, 1),
labels = c("DEO", "CON")),
GENDER = as.factor(GENDER))5 Generalised Linear Regression
In this chapter, we build on simple and multiple linear regression. All the lessons you learnt there still apply for building models with one or more predictors, but sometimes it is not appropriate to assume normality. It is a popular and convenient choice as assuming normality is often robust, but for some outcomes it would simply not be the appropriate choice. Generalised linear models allow you to specify a link and link function for the model residuals, so you can apply a linear model to alternative distributions. In this chapter, we will cover two types of generalised linear models: logistic regression and ordinal regression.
Chapter Intended Learning Outcomes (ILOs)
By the end of this chapter, you should be able to:
Understand how to run and interpret logistic regression.
Understand how to run and interpret ordinal regression.
5.1 Chapter preparation
In this chapter, we need a few different datasets, so we will introduce them as we need them.
5.1.1 Organising your files and project for the chapter
Before we can get started, you need to organise your files and project for the chapter, so your working directory is in order.
In your folder for statistics and research design
Stats_Research_Design, create a new folder called05_regression_generalised. Within05_regression_generalised, create two new folders calleddataandfigures.Create an R Project for
05_regression_generalisedas an existing directory for your chapter folder. This should now be your working directory.Create a new Quarto document and give it a sensible title describing the chapter, such as
05 Generalised Linear Regression. Save the file in your05_regression_generalisedfolder.We are working with a few data sets in this chapter, so please save the following zip file containing all the data files you need: Chapter 05 Data. Right click the link and select “save link as”, or clicking the link will save the file to your Downloads. Extract the files and make sure that you save them as “.csv”. Save or copy the files to your
data/folder within05_regression_generalised.
You are now ready to start working on the chapter!
5.2 Logistic Regression
5.2.1 Introduction to the dataset
For the guided examples, we have two datasets, but we will introduce them in turn. To demonstrate logistic regression, we will use data from Bostyn et al. (2018).
Bostyn et al. studied the classic trolley-dilemma in moral philosophy. In the typical format, a trolley (streetcar/tram) is travelling along tracks and will run over five people. However, you have the choice to pull a lever and divert the trolley to run over just one person. Although this would save lives, you must manually intervene to essentially kill one person. This is typically always a hypothetical scenario as it’s difficult to ask an ethics board for permission to run over people. In this study, Bostyn et al. compared a hypothetical version of the trolley-dilemma with a (seemingly) realistic version. Participants chose between not intervening and allowing five mice in a cage to be shocked with electricity or they could intervene and one mouse would be shocked instead. Do not worry, the mice were never shocked but participants did not know it at the time.
Their research question was: would there be a difference in moral decision-making when participants completed a hypothetical compared to a real version of the trolley-dilemma task? There was seemingly no hypothesis, so we will just focus on addressing the research question.
There is one independent variable (STUDY) to randomly allocate participants into one of two groups:
The “real” group (group
1in the data) attended a lab session where they saw two cages of real mice. They had 20 seconds to decide whether to press a button and divert the electric shock to the cage with one mouse.The hypothetical group (group
2in the data) completed a more traditional version of the study where they just responded on a computer for whether they would intervene or not after reading a description of allowing five mice to be shocked or choosing for one mouse to be shocked.
Participants completed a bunch of additional measures on moral judgement, empathy, psychopathy etc., but our main outcome of interest is whether they chose to intervene (1) or not (0) from the variable DECISION. They label these two decisions as deontological when people intervened and consequentialist when people did not intervene. For plotting, we will use the labels, but for the analyses we will use the 0s and 1s.
We first need to load some packages and the data for this task. If you do not have any of the packages, make sure you install them first.
As the first activity, try and test yourself by completing the following task list to practice your data wrangling skills. Create a final object called bostyn_data to be consistent with the tasks below. If you just want to focus on fitting the models, then you can just copy the code in the solution.
Try this
To wrangle the data, complete the following tasks:
-
Load the following packages. If you do not have them already, remember you will need to install them first if you are working on your own computer:
tidyverse emmeans ordinal sjPlot
You can complete the following tasks individually or combining things in one pipe, you just need a final object called
bostyn_data. Read the data filedata/bostyn_2018.csv.There are loads of variables in the data which you can explore in your own time, but for this chapter, just select the first four variables from
STUDYtoDECISION.There are a few missing values in
DECISION, so remove the NAs at this point.-
To help with plotting and modelling later, create two new variables:
Create a new variable called
studywhere you create a factor to recode the values fromSTUDY. 1 should be relabelled “Real” and 2 should be relabelled as “Hypothetical”.Create a new variable called
labelwhere you create a factor to recode the values fromDECISION. 0 should be relabelled “DEO” for deontological and 1 should be relabelled as “CON” for consequentialist.
To help with modelling later, convert
GENDERto a factor.
Show me the solution
You should have the following in a code chunk:
5.2.2 Exploratory data analysis
When starting any data analysis, it is important to visualise the data for some exploratory data analysis. Using the skills you developed in data skills for reproducible research, you can explore the data to understand its properties and look for potential patterns. In this scenario, a bar plot might be handy as we have a dichotomous outcome, so we can explore the frequency of responses across each group.
bostyn_data %>%
ggplot(aes(x = study, fill = label)) +
geom_bar(position = "dodge") +
scale_x_discrete(name = "Study") +
scale_y_continuous(name = "Frequency",
breaks = seq(0, 200, 50),
limits = c(0,200)) +
scale_fill_viridis_d(name = "Decision", option = "E") +
theme_minimal()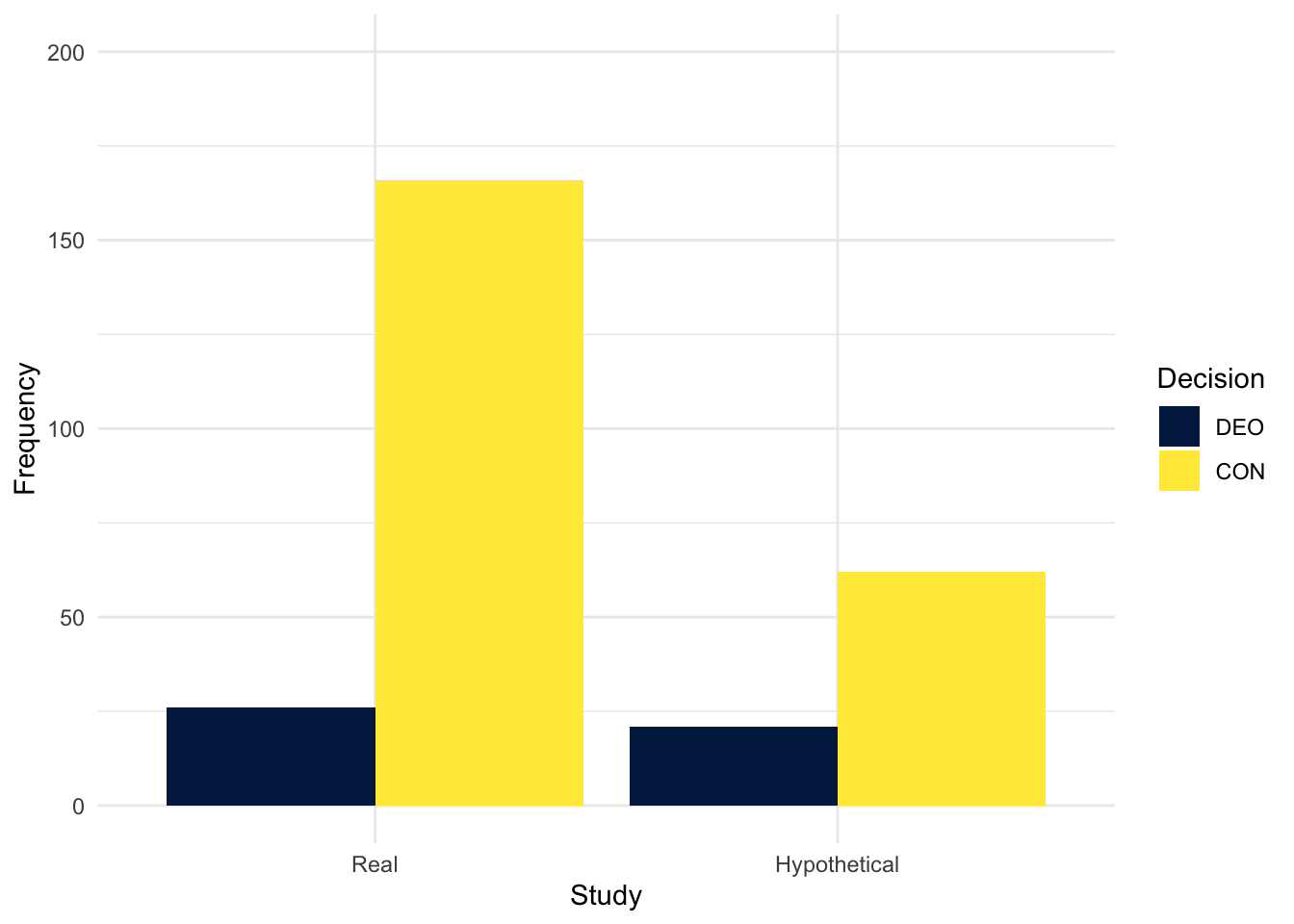
In the real group, there is a bigger difference in the number of people choosing to intervene and make a consequentialist response (1s in the data) compared to the hypothetical group where there is a smaller difference. The number of people choosing not to intervene and make a deontological response (0s in the data) is smaller in both groups, but it’s the proportional difference which changes.
Instead of counts, we can also express binary 0 and 1 data as a proportion or probability of intervening. If you take the mean of binary data, it tells you the proportion, so we can calculate the proportion of participant’s choosing to intervene as a consequentialist decision.
| study | proportion_con |
|---|---|
| Real | 0.8645833 |
| Hypothetical | 0.7469880 |
Participants in the real group (86%) were more likely to intervene than participants in the hypothetical group (75%). These are just descriptive statistics though, so you need to think about modelling to make inferences from these data.
5.2.3 Would linear regression work?
Warning
The most important part of data analysis is your role as the decision maker and thinking about what would be the most appropriate choice of model. Sometimes, there are equally valid approaches, while other times there is one better suited approach. If you apply an inappropriate test, R will gladly follow your instructions. Its your job to think critically about your modelling approach and check its an appropriate choice.
When we have a dichotomous outcome coded 0 and 1, it has numerical value, so R will happily apply regular linear regression.
Call:
lm(formula = DECISION ~ study, data = bostyn_data)
Residuals:
Min 1Q Median 3Q Max
-0.8646 0.1354 0.1354 0.1354 0.2530
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.86458 0.02698 32.041 <2e-16 ***
studyHypothetical -0.11760 0.04912 -2.394 0.0173 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.3739 on 273 degrees of freedom
Multiple R-squared: 0.02056, Adjusted R-squared: 0.01698
F-statistic: 5.732 on 1 and 273 DF, p-value: 0.01733It is somewhat interpretable as when you take the mean of binary data, you get the proportion. So, the intercept represents the proportion of consequentialist responses for those in the real group, and the slope coefficient represents the mean difference in proportion, suggesting there are .12/12% fewer consequentialist responses in the hypothetical group, which is statistically significant at \(\alpha\) = .05.
Although it works and we can make sense of the results, the question is whether it is an informative and appropriate way of modelling a binary outcome. Lets check the assumptions to see if anything looks off.
# Change the panel layout to 2 x 2
par(mfrow=c(2,2))
# plot the diagnostic plots
plot(bostyn_model1)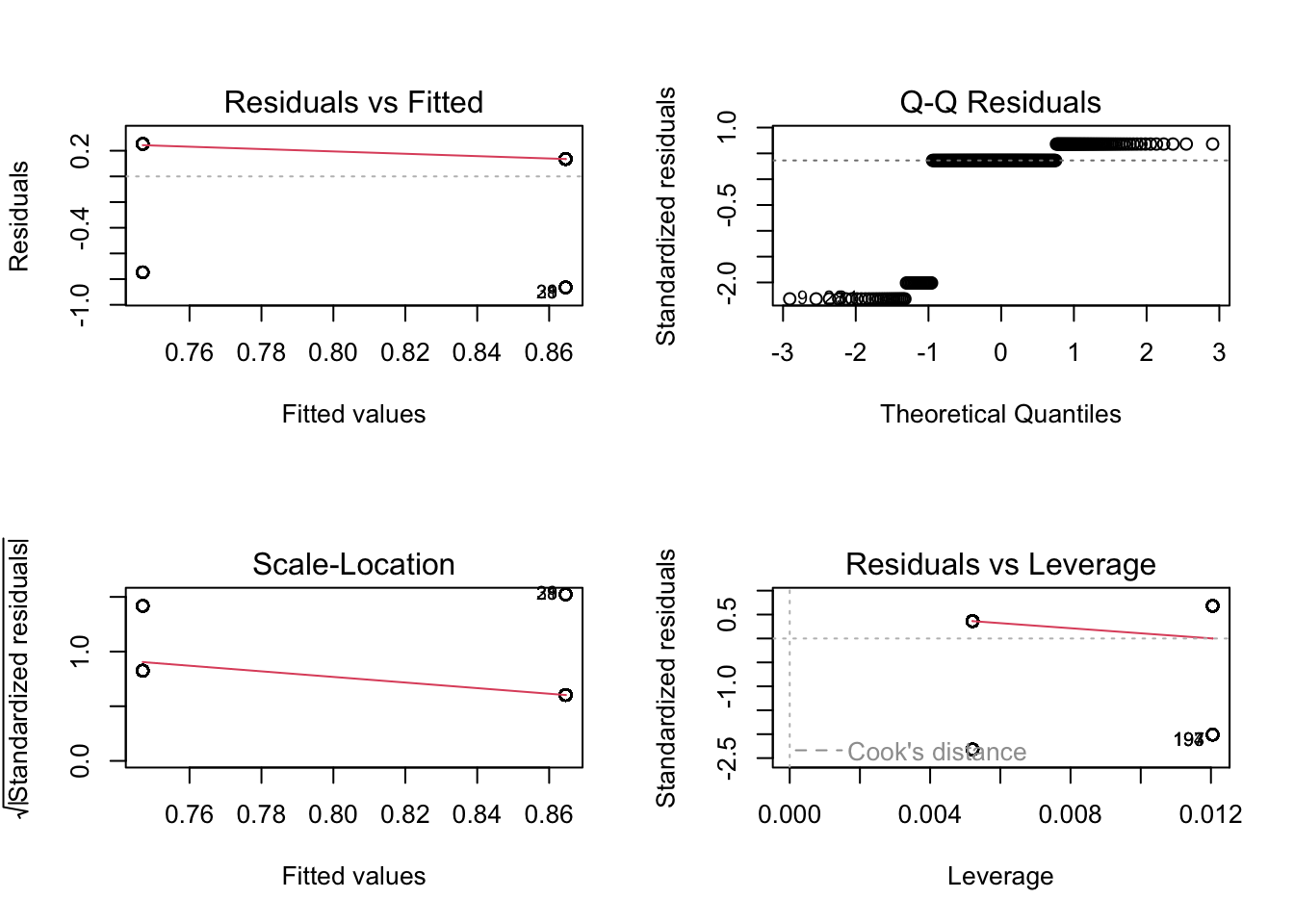
Now we can see the problems. Because we only have two possible outcomes, the assumption checks are all off. The qq plot in panel 2 particularly shows the problem, as there is a giant chunk missing where the values between 0 and 1 should be, at least theoretically if we assume normal residuals.
Now we can apply logistic regression to more appropriately model the dichotomous nature of the outcome.
5.2.4 Logistic regression
5.2.4.1 Generalised linear regression
In a linear model, we model the outcome as a product of an intercept, a slope, and error. Its that final error part which is why we have worried about normality so far. In a regular linear regression model, we need the model residuals (the difference between the expected and observed values) to be normally distributed.
Logistic regression is an adaptation of the linear regression framework we have worked with so far, where we can replace that error component. This is called generalised linear regression and we can specify a link and link function, instead of normal residuals being built into the model.
So far, we have always used lm(), but R comes with another function called glm() for generalised linear regression models. To demonstrate how we can set the link family, we can use it to recreate a regular linear regression model, but this time explicitly calling a normal distribution as the link (using its alternate name a Gaussian distribution) and “identity” as the link function.
bostyn_model1_glm <- glm(DECISION ~ study,
family = gaussian(link = "identity"),
data = bostyn_data)
summary(bostyn_model1_glm)
Call:
glm(formula = DECISION ~ study, family = gaussian(link = "identity"),
data = bostyn_data)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.86458 0.02698 32.041 <2e-16 ***
studyHypothetical -0.11760 0.04912 -2.394 0.0173 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for gaussian family taken to be 0.1398019)
Null deviance: 38.967 on 274 degrees of freedom
Residual deviance: 38.166 on 273 degrees of freedom
AIC: 243.34
Number of Fisher Scoring iterations: 2The link specifies the distribution family and the link function is the transformation for the model units. So, for our normal/Gaussian distribution, we have an identity link which essentially means no transformation, just the values we input. A normal distribution is described by a mean and standard deviation, so we just interpret the raw units in the model.
The results here are the same to the third decimal to show its an identical process. The only difference to our regular model output is the model fit statistics. Regular linear regression uses ordinal least squares to fit the model, whereas generalised linear regression fits the models using maximum likelihood. Holding everything else constant, this requires greater computing power, so its overkill to use glm() when you just want to assume normal/Gaussian errors, but its important to show the process behind these procedures.
Note
In this chapter, we are focusing on logistic regression and ordinal regression as variations of generalised linear regression. There are more possibilities though, so type ?family into the console to see the different families you could enter for the link and link function.
5.2.4.2 Logistic regression in glm()
After that brief detour, we will now actually fit the logistic regression model using glm(). As we have a dichotomous outcome, one useful distribution is the binomial. This applies when you want to calculate the probability of an dichotomous outcome from a series of successes (1s) and failures (0s). This models that probability nicely as it has a boundary of 0 or 0% (no successes) and 1 or 100% (all successes). Traditionally, we refer to successes and failures, but you can apply it to any binary outcome where one response is labelled 0 and the other response is labelled 1.
To apply the linear model element, we then use the “logit” link function as the unit transformation. Probability ranges between 0 and 1, odds range between 0 and infinity, but log odds (the logit bit) range between minus infinity and infinity, meaning we can fit straight lines to it. Let’s see what a logistic regression model looks like.
bostyn_model2 <- glm(DECISION ~ study,
family = binomial(link = "logit"),
data = bostyn_data)
summary(bostyn_model2)
Call:
glm(formula = DECISION ~ study, family = binomial(link = "logit"),
data = bostyn_data)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 1.8539 0.2109 8.790 <2e-16 ***
studyHypothetical -0.7713 0.3290 -2.344 0.0191 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 251.53 on 274 degrees of freedom
Residual deviance: 246.17 on 273 degrees of freedom
AIC: 250.17
Number of Fisher Scoring iterations: 4Waiting for profiling to be done... 2.5 % 97.5 %
(Intercept) 1.45962 2.289875
studyHypothetical -1.41563 -0.120060The model looks reassuringly similar. We have our coefficients for the intercept and slope, with their standard errors and p-values. There are no p-values for the model fit though as remember they are based on maximum likelihood, rather than least squares.
The main difference here is the interpretation of the coefficients. The link function is logit, so we get them in log odds, meaning the logarithm of an odds ratio (how likely something is to happen). These are not intuitive to interpret, so we can take the exponential to transform the slope coefficient from log odds to an odds ratio with its 95% CI.
# Take the exponential of the second coefficient to avoid typing it manually
exp(coef(bostyn_model2)[2]) #subset second componentstudyHypothetical
0.4624211 Waiting for profiling to be done... 2.5 % 97.5 %
(Intercept) 4.3043235 9.8737011
studyHypothetical 0.2427726 0.8868672An odds ratio is a ratio of the odds of an event happening in one group compared to the odds of an event happening in another group. In this context, a ratio of making a consequentialist decision (1s compared to 0s) in the real group compared to the hypothetical group.
An odds ratio of 1 means they are equally likely to happen. An odds ratio of less than 1 means something is less likely to happen, whereas more than 1 means something is more likely to happen. The odds ratio is 0.46 here, suggesting the odds of making a consequentialist decision is lower in the hypothetical group (our target group) compared to the real group (the reference group). Odds ratios below 1 can be tricky to interpret, so you can flip them around by taking the reciprocal.
studyHypothetical
2.162531 Waiting for profiling to be done... 2.5 % 97.5 %
(Intercept) 0.2323245 0.1012791
studyHypothetical 4.1190801 1.1275645Expressed this way, there are 2.16 (95% CI = [1.13, 4.12]) lower odds of making a consequentialist decision in the hypothetical group compared to the real group. In this model, it is statistically significant but we can see there is a decent amount of uncertainty around the estimate, spanning from 1.13 to 4.12.
Important
In this scenario, you would get the same reciprocal odds ratio if you changed the groups around with correction as the reference group. Taking the reciprocal is the same information expressed differently, but its important you are clear about the model estimates to avoid confusing your reader. If you do this yourself, make sure you explain what the model estimates were and how you took the reciprocal.
Returning to the idea of model comparison, we could compare the two GLM models using anova() and it will tell you the change in deviance (relating the maximum likelihood fitting process), but we can focus on comparing the AIC values for model fit between the two models. Lower values of AIC are better and if we subtract model 1 (the linear model) from model 2 (the logistic model), a negative difference would indicate better model fit from the ordinal model.
[1] 243.3384[1] 250.1702[1] 6.831779Interestingly, the second model actually has worse fit! There is less prediction error when we use the regular linear regression model compared to the logistic regression model. Given the assumptions and what we know of the design though, the logistic regression model would still be the sensible choice here. This reinforces why it is so important to recognise you as the decision maker and considering different sources of information.
5.2.4.3 Calculating the model probability estimates
Finally, there is a relationship between probability, odds, and log odds. We can use the coefficients to produce model estimates for the probability of a consequentialist decision in each group. Voas & Watt (2024) recommend this as the key output of a logistic regression model for helping to communicate your findings.
Warning
Relatedly, the whole purpose of Voas & Watt (2024) is to warn against a common misinterpretation of logistic regression. Often, people interpret the odds ratio as an increase in the likelihood of a response. For example, our odds ratio of 2.16 mistakenly interpreted as a consequentialist decision being just over twice as likely in the real group than the hypothetical group. In reality, it is a 2.16 higher odds of making a consequentialist decision, and the difference will be clearer once we express it as probabilities.
The logic is the same as for regular linear regression models, the intercept is the reference group, and the slope coefficient for your predictor is the shift across units of your outcome. First, we can calculate the model estimated probability for the reference group by taking the exponential of the intercept log odds divided by 1 plus the exponential intercept log odds:
\[ p = \dfrac{e^{b_0}}{1 + e^{b_0}}\]
Or as code:
# Estimated probability in the reference group
# We use coef() to isolate the model coefficients and subset the 1st item - the intercept
exp(coef(bostyn_model2)[1]) / (1 + exp(coef(bostyn_model2)[1]))(Intercept)
0.8645833 This means the estimated probability of a consequentialist decision in the real group is .86 or 86%.
Then for the hypothetical group, we repeat the process, but adding together the intercept and slope coefficient. Given the slope was negative, this is the equivalent of subtracting the slope. As an equation:
\[ p = \dfrac{e^{b_0 + b_1}}{1 + e^{b_0 + b_1}}\]
Then as code:
# Estimated probability in the target group
# We use coef() to isolate the model coefficients and subset the 1st item - the intercept
# We then add the 2nd item in coef() - the slope
exp(coef(bostyn_model2)[1] + coef(bostyn_model2)[2]) / (1 + exp(coef(bostyn_model2)[1] + coef(bostyn_model2)[2]))(Intercept)
0.746988 This means the estimated probability of a consequentialist decision in the hypothetical group is .75 or 75%. These values line up nicely with our original summary statistics, but keep in mind they are model estimates. They are closer here as its a very simple model and we are demonstrating the principles, but they will not line up this close when you have more complex models with marginal effects to understand.
5.2.4.4 Using emmeans to get model estimates
Another way of getting model estimates is using the emmeans() function from the
# logistic regression model as the object
# Specifying Condition as the predictor we want marginal effects for
emmeans(bostyn_model2, specs = "study") study emmean SE df asymp.LCL asymp.UCL
Real 1.85 0.211 Inf 1.441 2.27
Hypothetical 1.08 0.252 Inf 0.588 1.58
Results are given on the logit (not the response) scale.
Confidence level used: 0.95 These are still in log odds units, so you can calculate the probability using the same equation as before:
\[ p = \dfrac{e}{1 + e}\]
To make it less repetitive, you can use the following user-generated function and enter all the relevant values as a vector:
probability_from_logit <- function(x){
return(
exp(x) / (1 + exp(x))
)
}
probability_from_logit(c(1.85, # estimate
1.44, # lower 95% CI
2.27)) # upper 95% CI[1] 0.8641271 0.8084547 0.9063618Which corresponds nicely with what we reconstructed from the model coefficients.
5.2.4.5 Plotting logistic regression models
Like any model, it will make your life and the lives of your reader much easier to supplement your statistics with a plot informatively showing the model estimates. We can use the
# sjPlot makes it easy to plot estimates from the model
plot_model(bostyn_model2, # You enter the model object
type = "pred", # The type of plot you want to create
terms = "study") # The predictor(s)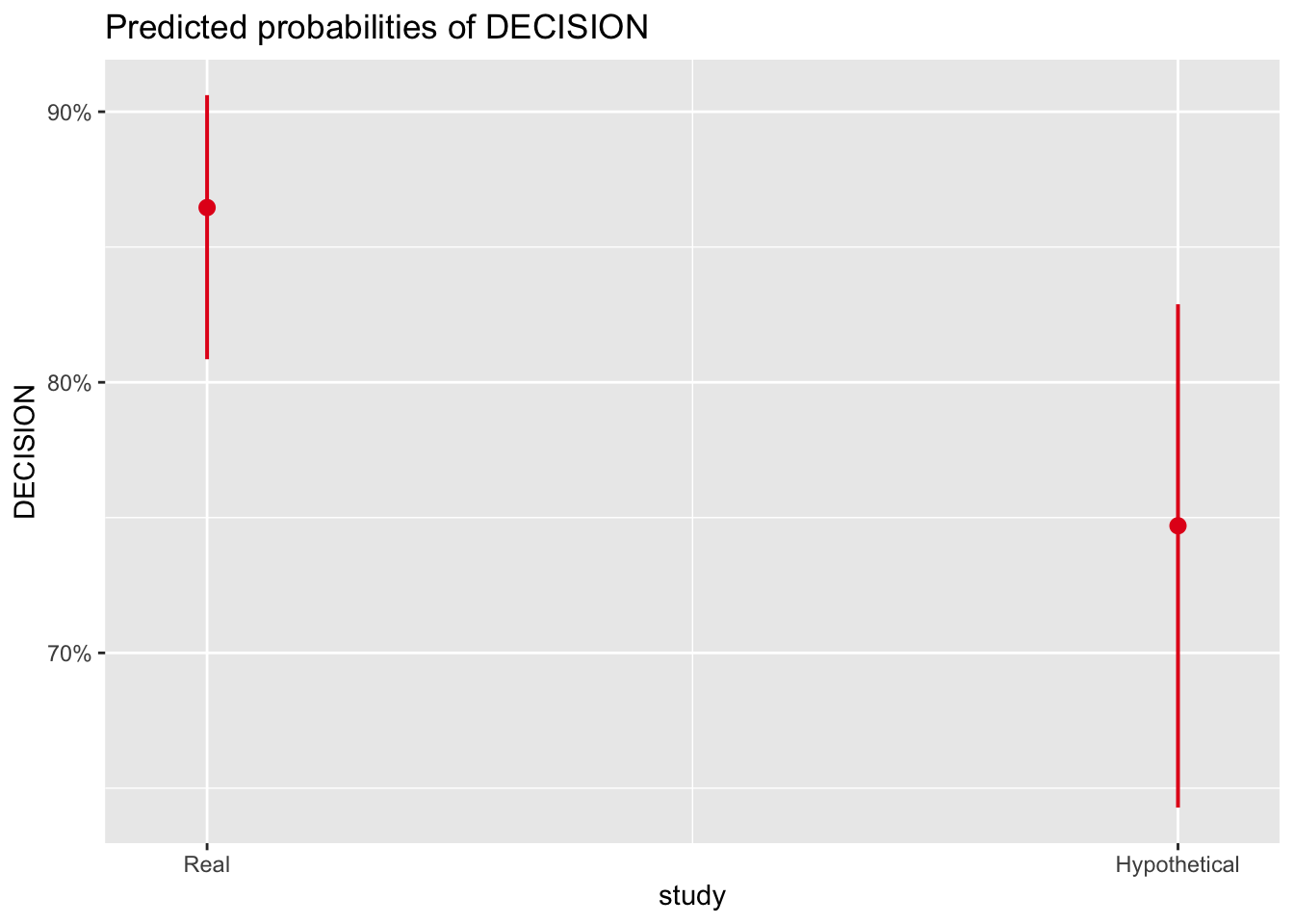
Plus some additional arguments and ggplot() layers to tidy things up. Helpfully, it recognises the y-axis is a probability and amends the scale. Unhelpfully, if you want to change the limits etc., you need to tidy the scale up again or it reverts back to proportion.
plot_model(bostyn_model2,
type = "pred",
terms = "study",
axis.title = c("Real or Hypothetical Scenario", "Probability Consequentialist Decision (%)")) +
scale_y_continuous(labels = scales::percent, # setting to convert y to percent
limits = c(0.5, 1)) + # original units are proportion
theme_classic() +
labs(title = "")Scale for y is already present.
Adding another scale for y, which will replace the existing scale.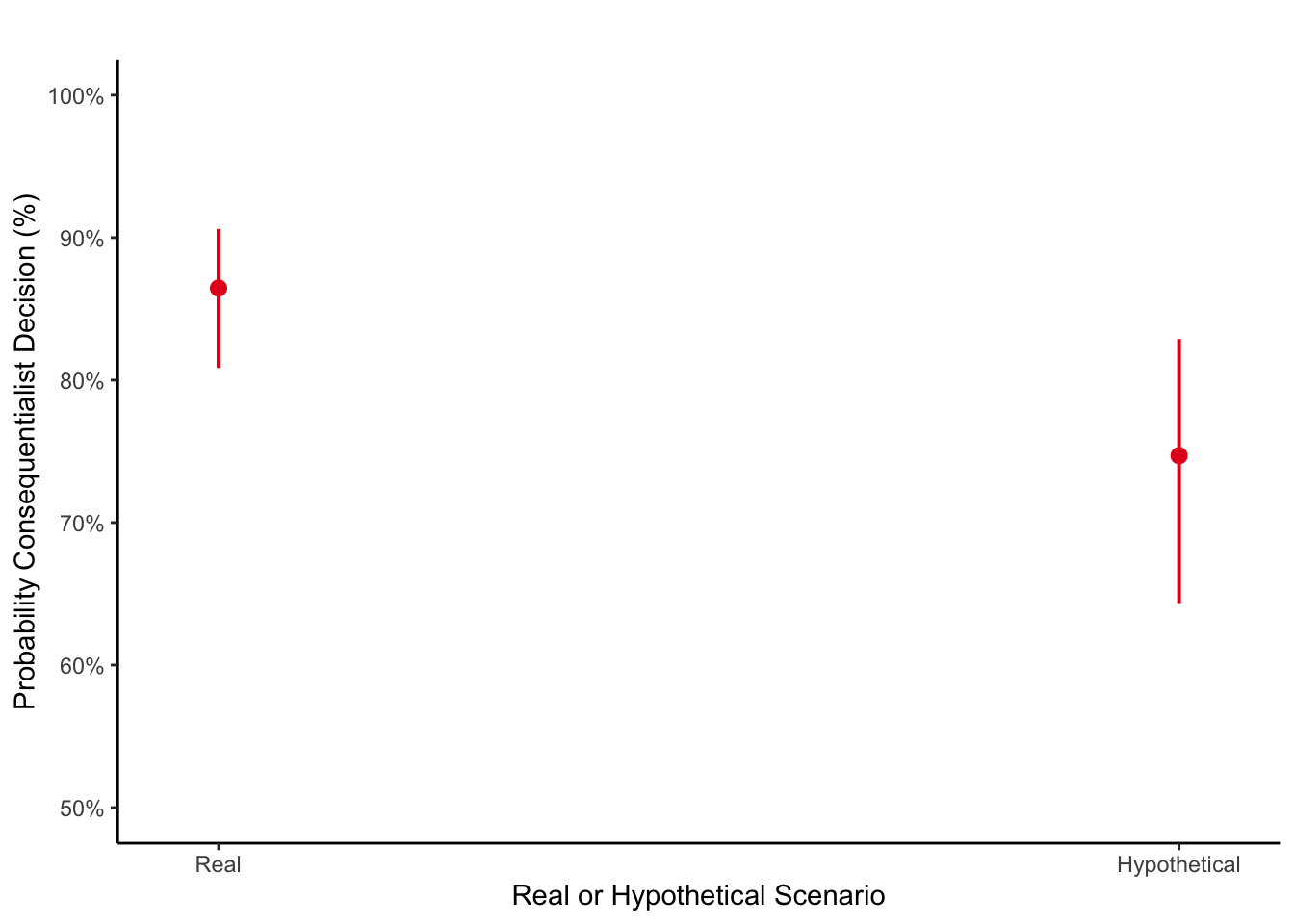
5.3 Ordinal Regression
5.3.1 Introduction to the dataset
To demonstrate ordinal regression, we will use data from Brandt et al. (2014). The aim of Brandt et al. was to replicate a relatively famous social psychology study (Banerjee et al., 2012) on the effect of recalling unethical behaviour on the perception of brightness.
In common language, unethical behaviour is considered as “dark”, so the original authors designed a priming experiment where participants were randomly allocated to recall an unethical behaviour or an ethical behaviour from their past. Participants then completed a series of measures including their perception of how bright the testing room was. Brandt et al. were sceptical and wanted to replicate this study to see if they could find similar results.
Participants were randomly allocated (ExpCond) to recall an unethical behaviour (1; n = 49) or an ethical behaviour (0; n = 51). The key outcome was their perception of how bright the room was (welllit), from 1 (not bright at all) to 7 (very bright). The research question was: Does recalling unethical behaviour lead people to perceive a room as darker than if they recall ethical behaviour?
# Brandt data for ordinal regression
Brandt_data <- read_csv("data/Brandt_unlit.csv") %>%
mutate(ExpCond = as.factor(case_when(ExpCond == 1 ~ 0, # Ethical
ExpCond == -1 ~ 1))) # UnethicalRows: 100 Columns: 7
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (7): BasicFollowedDirections, ExpCond, flagged, ppnr, bright, welllit, W...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.5.3.2 Exploratory data analysis
When starting any data analysis, it is important to visualise the data for some exploratory data analysis. Using the skills you developed in data skills for reproducible research, you can explore the data to understand its properties and look for potential patterns. We can create a boxplot to get a brief overview of how perceived brightness changes depending on the experimental condition.
Brandt_data %>%
ggplot(aes(x = ExpCond, y = welllit)) +
geom_boxplot() +
scale_x_discrete(name = "Ethical Group", labels = c("Ethical", "Unethical")) +
scale_y_continuous(name = "Brightness Rating", breaks = 1:7) +
theme_minimal()
There are some signs of the outcome being ordinal, but its not super obvious. We can create a histogram showing the distribution of brightness rating by group, to see how discrete the data are.
Brandt_data %>%
ggplot(aes(x = welllit, fill = ExpCond)) +
geom_histogram(position = "dodge") +
scale_x_continuous(name = "Brightness Rating", breaks = 1:7) +
scale_y_continuous(name = "Count", breaks = seq(0, 20, 5), limits = c(0, 20)) +
theme_minimal()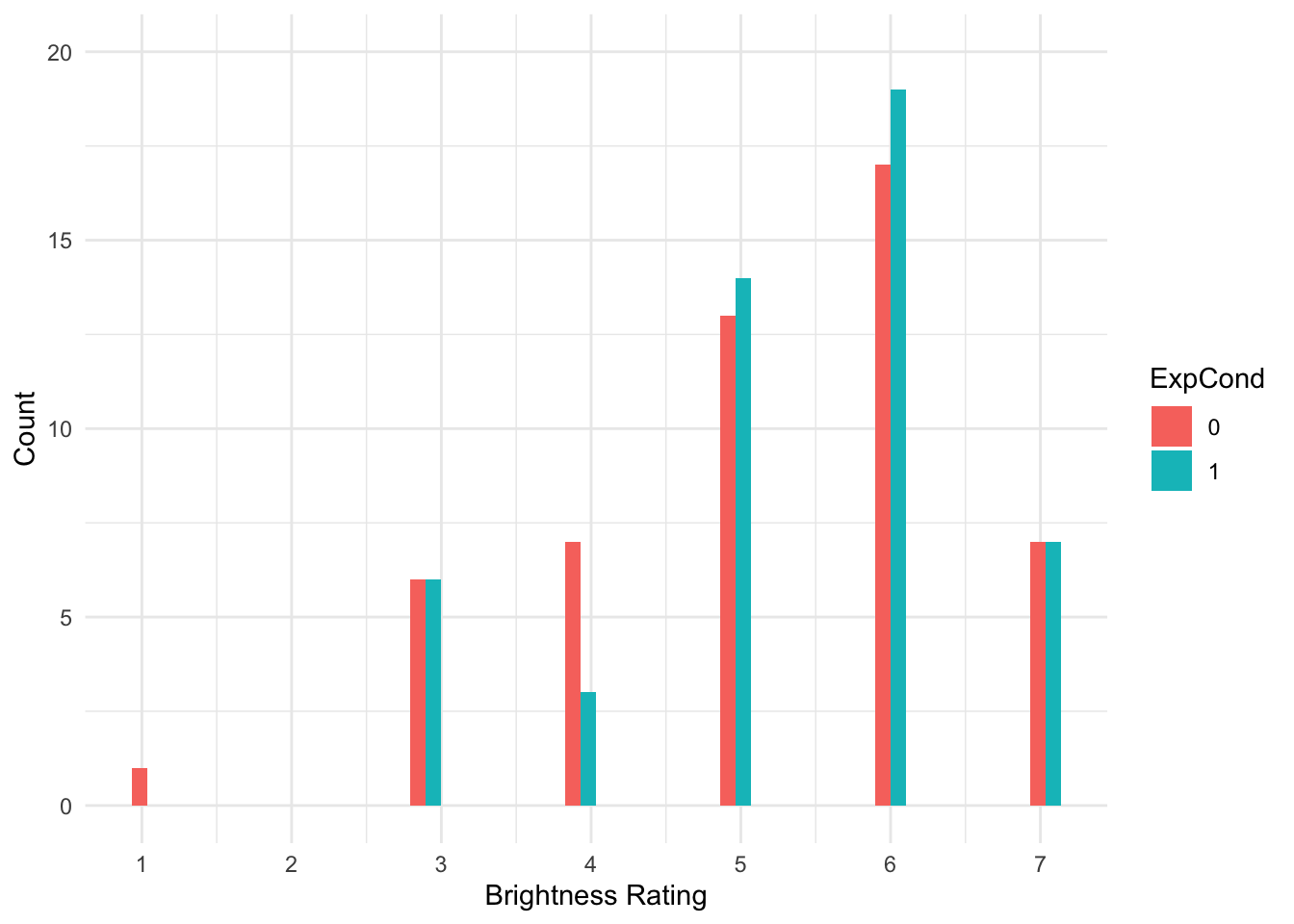
That’s much better. Now, we can see the clearly ordinal nature of brightness rating and how participants can only respond on the integer 1-7 scale.
5.3.3 Would linear regression work?
Warning
The most important part of data analysis is your role as the decision maker and thinking about what would be the most appropriate choice of modelling. Sometimes, there are equally valid approaches, while other times there is one better suited approach. If you apply an inappropriate test, R will gladly follow your instructions. Its your job to think critically about your modelling approach and check its an appropriate choice.
R will happily let us apply simple linear regression to predict brightness rating (welllit) from the categorical predictor of experimental condition (ExpCond). This is by far the most common approach to tackling ordinal outcomes in psychology, particularly when you take the mean or sum of multiple ordinal items, so it looks a little more continuous. If you meet the other assumptions of linear regression, it can often be a pragmatic and robust approach.
# Linear model predicting brightness rating from condition
brandt_model1 <- lm(welllit ~ ExpCond, data = Brandt_data)
# model summary
summary(brandt_model1)
Call:
lm(formula = welllit ~ ExpCond, data = Brandt_data)
Residuals:
Min 1Q Median 3Q Max
-4.1569 -0.3673 0.2379 0.8431 1.8431
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 5.1569 0.1779 28.992 <2e-16 ***
ExpCond1 0.2105 0.2541 0.828 0.409
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.27 on 98 degrees of freedom
Multiple R-squared: 0.006953, Adjusted R-squared: -0.00318
F-statistic: 0.6861 on 1 and 98 DF, p-value: 0.4095 2.5 % 97.5 %
(Intercept) 4.8038772 5.5098483
ExpCond1 -0.2937809 0.7147492The intercept suggests the mean brightness rating for participants in the ethical group was 5.16. The coefficient and model are not statistically significant - explaining very little variance in the outcome - and suggests those in the unethical group had a mean increase in brightness rating of 0.21 [-0.29, 0.71].
The first problem comes in the interpretation. As a linear model expecting normally distributed residuals, we get means for the intercept and coefficient, and they could - at least theoretically - be any values. So, we get an average of 5.16 and 5.37 for our two groups, but the scale items could only be integers from 1-7. So, you can question how informative it is to treat these data as interval, when they are only labels for arbitrary numbers ranging from 1 (not bright at all) to 7 (very bright).
The second problem comes in the assumptions of the model. If the means are around the middle of the scale, it can behave approximately normal. If the means are closer to the boundaries, then you start running into problems as the residuals that the model thinks are theoretically boundless, hit a boundary. Let’s look at the checks for this model.
# Change the panel layout to 2 x 2
par(mfrow=c(2,2))
# plot the diagnostic plots
plot(brandt_model1)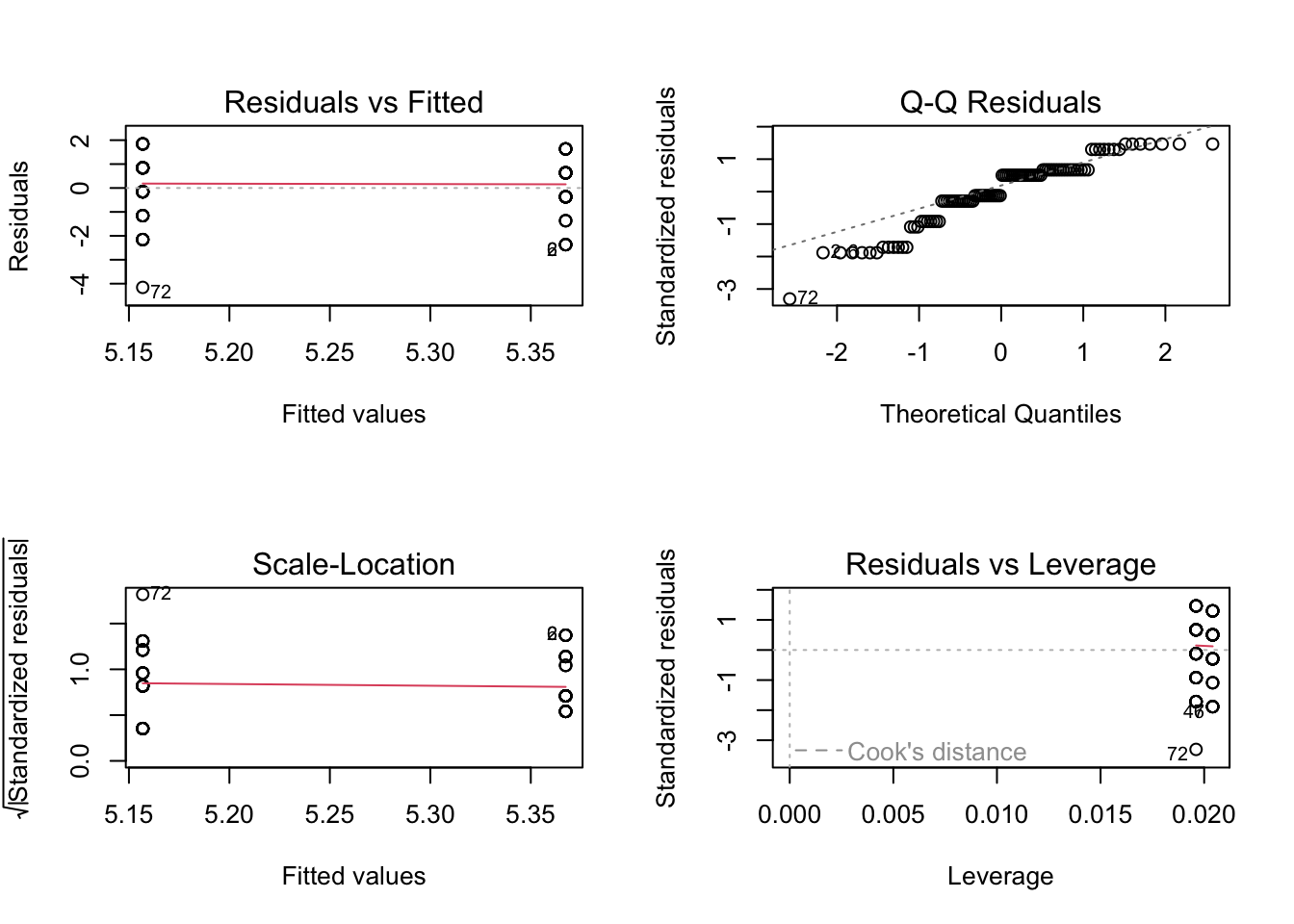
The qq plot in pane 2 of the residuals against the theoretical distribution is key here. Most of the points follow the dashes line, but it shifts away towards the lower boundary. There are also telltale signs of discrete ordinal data as the residuals move in set points. This is because the outcome can only be 1-7, but the theoretical quantiles are boundless.
So, while the assumptions do not look catastrophic, we will explore how we can model the ordinal nature of the outcome better.
5.3.4 Ordinal regression
Ordinal regression models are a kind of logistic regression model. They are also known as cumulative link or ordered logit models. They work on the same logic as logistic regression where we want to model the probability of a discrete outcome, but instead of only two possible outcomes, ordinal regression models split a scale up into an ordered series of discrete outcomes. Between each scale point, the model estimates the threshold and sees how the outcome shifts across your predictor(s).
To get an idea of cumulative probability, we can plot the Brandt et al. data to see how the cumulative percentage of responses across the scale shifts for each group.
Brandt_data %>%
ggplot(aes(x = welllit, colour = ExpCond)) +
stat_ecdf() +
scale_x_continuous(breaks = 1:7, name = "Brightness Perception") +
scale_y_continuous(breaks = seq(0, 1, 0.2), name = "Cumulative Percent") +
theme_minimal()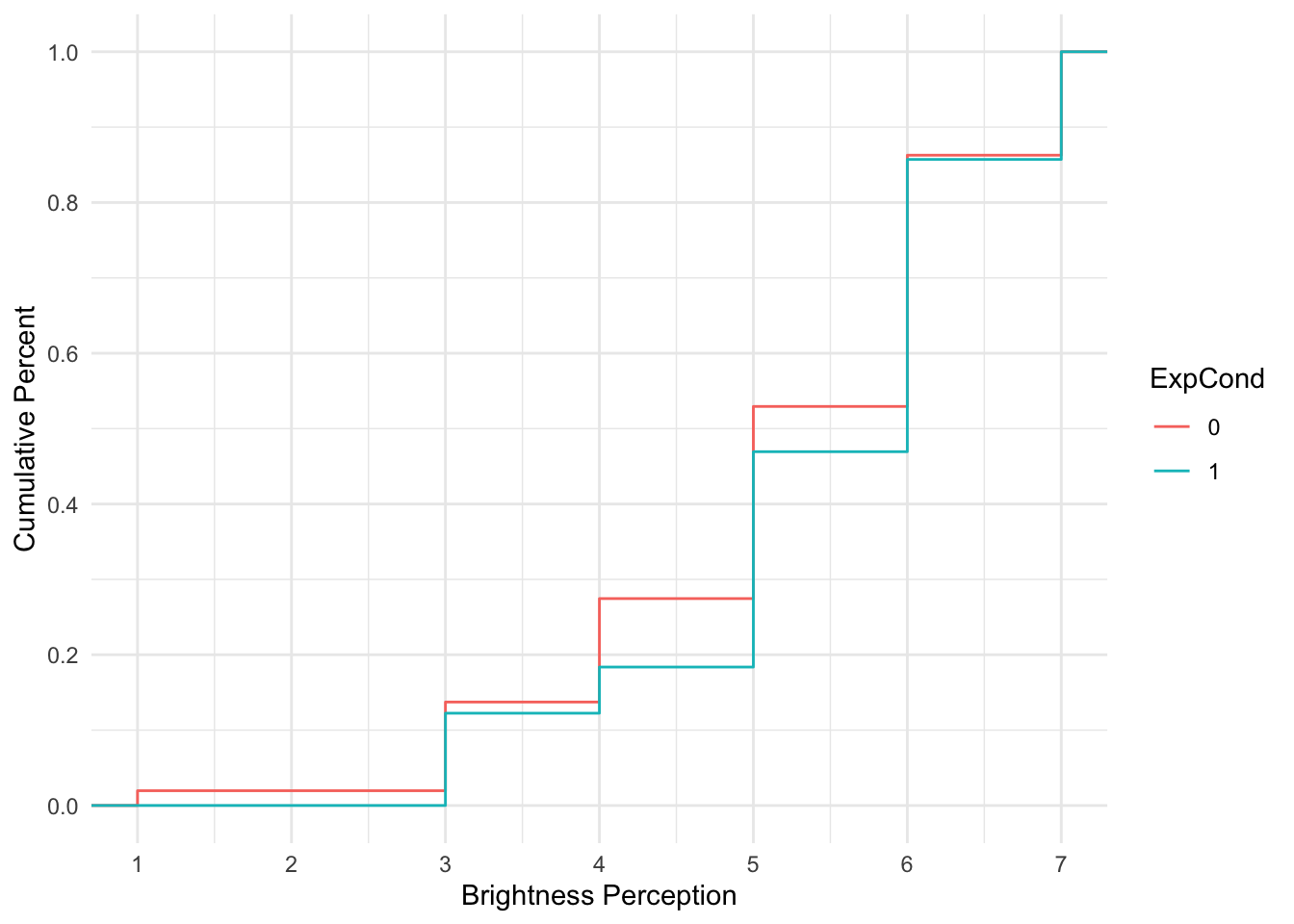
For each group, the lines corresponds with the cumulative percentage at each scale point. When the line is horizontal, there is no change. When the line moves vertically, it represents the next percentage increase, adding to the cumulative percentage from the previous shift, until you reach 100%.
Ordinal regression models estimate these shifts in probability and you get k-1 estimates for the thresholds, meaning you get one fewer estimate than the total number of scale points. Behind the scenes, the model interprets the outcome as a Gaussian looking latent variable, meaning the ordinal scale points are tapping into some kind of construct, but honouring there are discrete scale points.
The coefficient in the model represents the probability shift of a 1 scale point increase from one distribution to another on the scale of your predictors. So, for every 1-unit increase in a continuous predictor, you see how the probability shifts, or how the probability shifts for the difference between two groups in a categorical predictor. A positive slope coefficient would mean an increase in probability along your predictor scale, while a negative slope coefficient would mean a decrease in probability along your predictor scale.
We will fit ordinal regression models using the
First, we need to convert the outcome into a factor, so there are a discrete ordered number of points.
Brandt_data <- Brandt_data %>%
mutate(WellLitFactor = factor(welllit))
levels(Brandt_data$WellLitFactor)[1] "1" "3" "4" "5" "6" "7"We can see here the scale points are in ascending order as we want them to be, and no one in the data ever responded 2. Next, we can fit our ordinal regression model using the same format as all our regression models.
# clm = cumulative link model
brandt_model2 <- clm(WellLitFactor ~ ExpCond, data = Brandt_data)
summary(brandt_model2)formula: WellLitFactor ~ ExpCond
data: Brandt_data
link threshold nobs logLik AIC niter max.grad cond.H
logit flexible 100 -152.47 316.94 6(0) 1.10e-07 6.9e+01
Coefficients:
Estimate Std. Error z value Pr(>|z|)
ExpCond1 0.2594 0.3606 0.719 0.472
Threshold coefficients:
Estimate Std. Error z value
1|3 -4.4751 1.0181 -4.395
3|4 -1.7798 0.3403 -5.231
4|5 -1.0845 0.2921 -3.713
5|6 0.1309 0.2703 0.484
6|7 1.9504 0.3460 5.637 2.5 % 97.5 %
ExpCond1 -0.4465061 0.9702407In the first segment of the output, its somewhat similar to the other models we have fitted, but there is no intercept at the top. We just have the slope coefficients for each predictor (1 in this case), then the threshold coefficients for k-1 scale points.
As this is an adapted version of logistic regression, the units are in log odds. So, they are easier to interpret as an odds ratio by taking the exponential.
ExpCond1
1.296112 2.5 % 97.5 %
ExpCond1 0.6398599 2.63858The results correspond with what we plotted previously, we have an odds ratio of 1.30 [0.64, 2.64], meaning there are 1.3 higher odds of a brighter rating in the unethical condition compared to the ethical condition. However, the confidence interval is pretty wide here and the p-value is not statistically significant, so we cannot conclude there is a shift in probability between the two groups here.
Returning to the idea of model comparison, it will not let us compare them using anova() as we cannot compare the same outcome when its numeric vs a factor. However, we can compare the AIC values for model fit between the two models. Lower values of AIC are better and if we subtract model 1 (the linear model) from model 2 (the ordinal model), a negative difference would indicate better model fit from the ordinal model.
That does seem to be the case here. Although both models were non-significant, modelling the outcome as ordinal - reassuringly - fits the data better with less prediction error.
5.3.4.1 Breaking down threshold coefficients
We would normally focus on the coefficient as the main outcome of the modelling, but we can also break down the threshold coefficients so they are not a mystery. These represent the estimates for the cumulative probability of choosing a given scale point. These relate to the reference group, so we see the cumulative probability of the ethical condition. Remember, these are still in log odds, so we can calculate the probability like we did for logistic regression by dividing the odds ratio by 1 plus the odds ratio.
Note
The code below uses coef() function and subsetting (the [1]etc.) to avoid writing out the numbers manually and reduce copy and paste errors. Try coef(brandt_model2) in the console to see the coefficients it returns.
# Cumulative percentage for ethical group choosing less than 3 - coefficient 1
exp(coef(brandt_model2)[1]) / (1 + exp(coef(brandt_model2)[1])) 1|3
0.01126058 # Cumulative percentage for ethical group choosing less than 4 - coefficient 2
exp(coef(brandt_model2)[2]) / (1 + exp(coef(brandt_model2)[2])) 3|4
0.1443283 # Cumulative percentage for ethical group choosing less than 5- coefficient 3
exp(coef(brandt_model2)[3]) / (1 + exp(coef(brandt_model2)[3])) 4|5
0.2526636 # Cumulative percentage for ethical group choosing less than 6- coefficient 4
exp(coef(brandt_model2)[4]) / (1 + exp(coef(brandt_model2)[4])) 5|6
0.5326661 # Cumulative percentage for ethical group choosing less than 7- coefficient 5
exp(coef(brandt_model2)[5]) / (1 + exp(coef(brandt_model2)[5])) 6|7
0.8754855 This means choosing less than 3 (remember no one responded 2) represents .011 or 1.12%. Choosing less than 4 represents .144 or 14.4%, and so on. Once we get to the final threshold, this represents less than 7 at .875/87.5%. The cumulative probability of 7 or less is then 1/100%, which is why you get k-1 thresholds. So, you can work that final step out as 1 - .875 = .125/12.5%.
These cumulative percentage estimates are for the reference group (ethical), so you could calculate the estimate for the unethical group by subtracting the slope coefficient (0.2594) from each threshold. For example, for the first threshold:
# Cumulative percentage for unethical group choosing less than 3
# Coefficient 1 minus coefficient 6 as the slope is weirdly the last one here, not the first
exp(coef(brandt_model2)[1] - coef(brandt_model2)[6]) / (1 + exp(coef(brandt_model2)[1] - coef(brandt_model2)[6])) 1|3
0.008710377
Note
As before, we are using the coef() function and subsetting (the [1]etc.) to avoid writing out the numbers manually and reduce copy and paste errors. This time, we are using two coefficients to subtract the slope coefficient from each threshold coefficient. So, if you apply this to a new data set, make sure you check how many coefficients there are to subset them accurately.
This means the cumulative probability estimate for less than 3 is .0087 or 0.87% in the unethical group.
5.3.4.2 Different threshold assumptions
Finally, the default option in flexible thresholds between scale points. This estimates a coefficient for threshold and makes the fewest assumptions about the outcome. Alternative options are equidistant which assume evenly spaced scale points, or symmetric which assume scale points are evenly spaced above and below the scale center. These two make stronger assumptions about the outcome but require fewer parameters, so you would need to think carefully about whether they would suit the outcome you are modelling.
To see how the equidistant option would compare:
# clm = cumulative link model with equidistant thresholds
brandt_model3 <- clm(WellLitFactor ~ ExpCond,
data = Brandt_data,
threshold = "equidistant")
summary(brandt_model3)formula: WellLitFactor ~ ExpCond
data: Brandt_data
link threshold nobs logLik AIC niter max.grad cond.H
logit equidistant 100 -158.95 323.90 5(0) 7.75e-11 8.3e+01
Coefficients:
Estimate Std. Error z value Pr(>|z|)
ExpCond1 0.2728 0.3583 0.761 0.447
Threshold coefficients:
Estimate Std. Error z value
threshold.1 -3.7721 0.4394 -8.585
spacing 1.3626 0.1280 10.647This time, you only get one threshold estimate and a spacing parameter. Instead of calculating the cumulative probability at each threshold, you must successively add them together:
# Cumulative percentage for ethical group choosing less than 3 equally spaced
exp(coef(brandt_model3)[1] + 0 * coef(brandt_model3)[2]) / (1 + exp(coef(brandt_model3)[1] + 0 * coef(brandt_model3)[2]))threshold.1
0.02248644 # Cumulative percentage for ethical group choosing less than 4 equally spaced
exp(coef(brandt_model3)[1] + 1 * coef(brandt_model3)[2]) / (1 + exp(coef(brandt_model3)[1] + 1 * coef(brandt_model3)[2]))threshold.1
0.08245417 5.4 Test Yourself
Now you have followed along to a guided example, it is important you can transfer your knowledge to a new scenario. So, we have a new data set for you to try out your understanding of these techniques on. Follow the instructions below and answer the questions. The solution is there to check your answers against, but make sure you try the activities independently first.
5.4.1 Independent logistic regression
For an independent activity, we will use the same data set from Bostyn et al. (2018), but this time using a couple of extra predictors. If you are coming to this fresh, make sure to remind yourself of the data set outlined in the logistic regression section and load the data.
Try this
From here, apply what you learnt in the guided example for logistic regression to this new independent task and complete the questions below to check your understanding.
In Bostyn et al. (2018), they actually fit a multiple logistic regression model where they include three predictors. They include study as the key predictor of interest, but they also control for AGE and GENDER as additional predictors. Fit this model to create a new object called bostyn_model3 and answer the following questions.
In the new model, our key predictor of
studyis statistically . The two new predictors ofAGEandGENDERare statistically .The slope for
studyis still in log odds and negative (unless you flipped the groups). If you take the reciprocal of the exponential slope, the odds ratio for the predictor to 2 decimals is [lower 95% CI = , upper 95% CI = ].This suggests there are lower odds of making a consequential decision in the group compared to the group.
Rounding to 1 decimal, the estimated probability of making a consequential decision in the real group is % (95% CI = , ) and the estimated probability in the hypothetical group is % (95% CI = , ).
Show me the solution
The first step is fitting the model with three individual predictors.
bostyn_model3 <- glm(DECISION ~ study + AGE + GENDER,
family = binomial(link = "logit"),
data = bostyn_data)
summary(bostyn_model3)
Call:
glm(formula = DECISION ~ study + AGE + GENDER, family = binomial(link = "logit"),
data = bostyn_data)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -3.8900 3.4952 -1.113 0.2657
studyHypothetical -0.8019 0.3361 -2.385 0.0171 *
AGE 0.3075 0.1913 1.608 0.1078
GENDER1 0.1940 0.3920 0.495 0.6207
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 251.53 on 274 degrees of freedom
Residual deviance: 242.13 on 271 degrees of freedom
AIC: 250.13
Number of Fisher Scoring iterations: 4Given the model, you can take the reciprocal of the exponential for the slope estimate and its 95% confidence interval. You do not need the reciprocal if you flipped the groups and estimate is above 1.
studyHypothetical
2.22971 Waiting for profiling to be done... 2.5 % 97.5 %
(Intercept) 80279.914577 0.08384154
studyHypothetical 4.312262 1.14763061
AGE 1.040199 0.48957669
GENDER1 1.737032 0.36872266Finally, you can calculate the estimated probability of making a consequentialist decision in each group by using the emmeans() function and our user-generated conversion function. If you calculated it manually with the other methods, that’s fine too.
study emmean SE df asymp.LCL asymp.UCL
Real 1.94 0.228 Inf 1.493 2.39
Hypothetical 1.14 0.281 Inf 0.587 1.69
Results are averaged over the levels of: GENDER
Results are given on the logit (not the response) scale.
Confidence level used: 0.95 [1] 0.8743521 0.8160783 0.9160616[1] 0.7576796 0.6433651 0.84422425.4.2 Independent ordinal regression
For an independent activity, we will use data from Schroeder & Epley (2015). The aim of the study was to investigate whether delivering a short speech to a potential employer would be more effective at landing you a job than writing the speech down and the employer reading it themselves. Thirty-nine professional recruiters were randomly assigned to receive a job application speech as either a transcript for them to read, or an audio recording of the applicant reading the speech.
The recruiters then rated the applicants on perceived intellect, their impression of the applicant, and whether they would recommend hiring the candidate. All ratings were originally on a rating scale ranging from 0 (low intellect, impression etc.) to 10 (high impression, recommendation etc.), with the final value representing the mean across several items.
For this example, we will focus on the hire rating (variable Hire_Rating to see whether the audio condition had a would lead to higher ratings than the transcript condition (variable CONDITION).
Try this
From here, apply what you learnt in the guided example for ordinal regression to this new independent task and complete the questions below to check your understanding. Remember you will need to treat the outcome as a factor to fit the ordinal model. The answers are based on the default approach for estimating flexible thresholds.
The experimental condition is a and predictor of hire rating.
Rounding to two decimals, the slope coefficient converted to an odds ratio is [lower 95% CI = , upper 95% CI = ].
This suggests there are higher odds of a larger hire rating in the condition compared to the condition.
Rounding to three decimals, the estimated cumulative probability for the transcript group choosing a hire rating of lower than 3 (hint: coefficient 3) is and the cumulative probability for the audio group choosing a hire rating of lower than 3 (hint: coefficient 3 minus coefficient 9) is .
Show me the solution
First, we need to convert hire rating to a factor for the ordinal model to work.
We can explore the distribution of the two groups and see there is a clearer difference here, with more low ratings in the transcript (0) group and more high ratings in the audio (1) group.
schroeder_data %>%
ggplot(aes(x = Hire_Rating, fill = condition)) +
geom_histogram(position = "dodge") +
scale_x_continuous(breaks = 0:8, name = "Hire Rating") +
theme_minimal()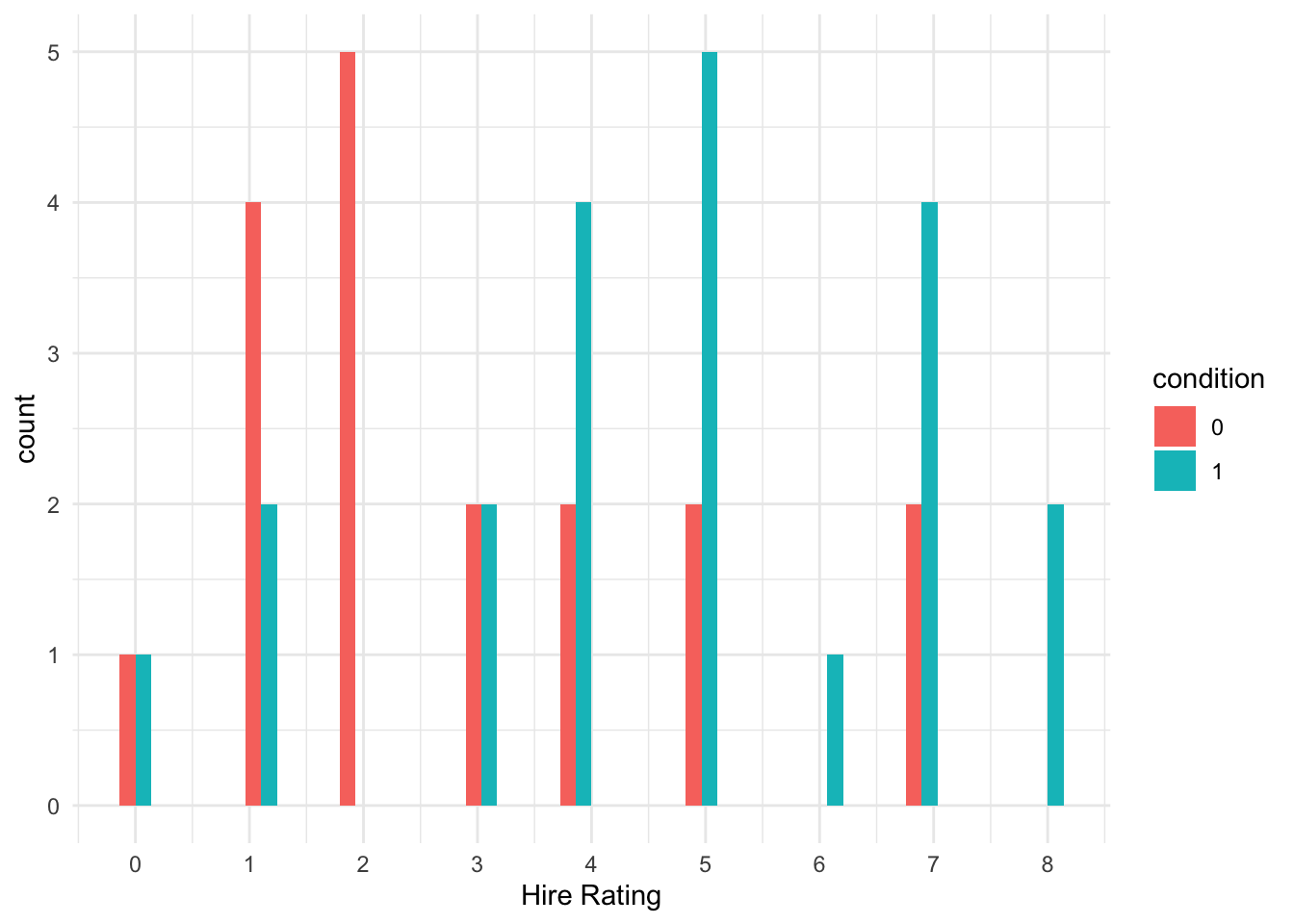
Alternatively, we can visualise the cumulative probability and see how it climbs steeper for the transcript group (more lower responses) and shallow for the audio group (more higher responses).
schroeder_data %>%
ggplot(aes(x = Hire_Rating, colour = condition)) +
stat_ecdf() +
scale_x_continuous(breaks = 0:8, name = "Hire Rating") +
scale_y_continuous(breaks = seq(0, 1, 0.2), name = "Cumulative Percent") +
theme_minimal()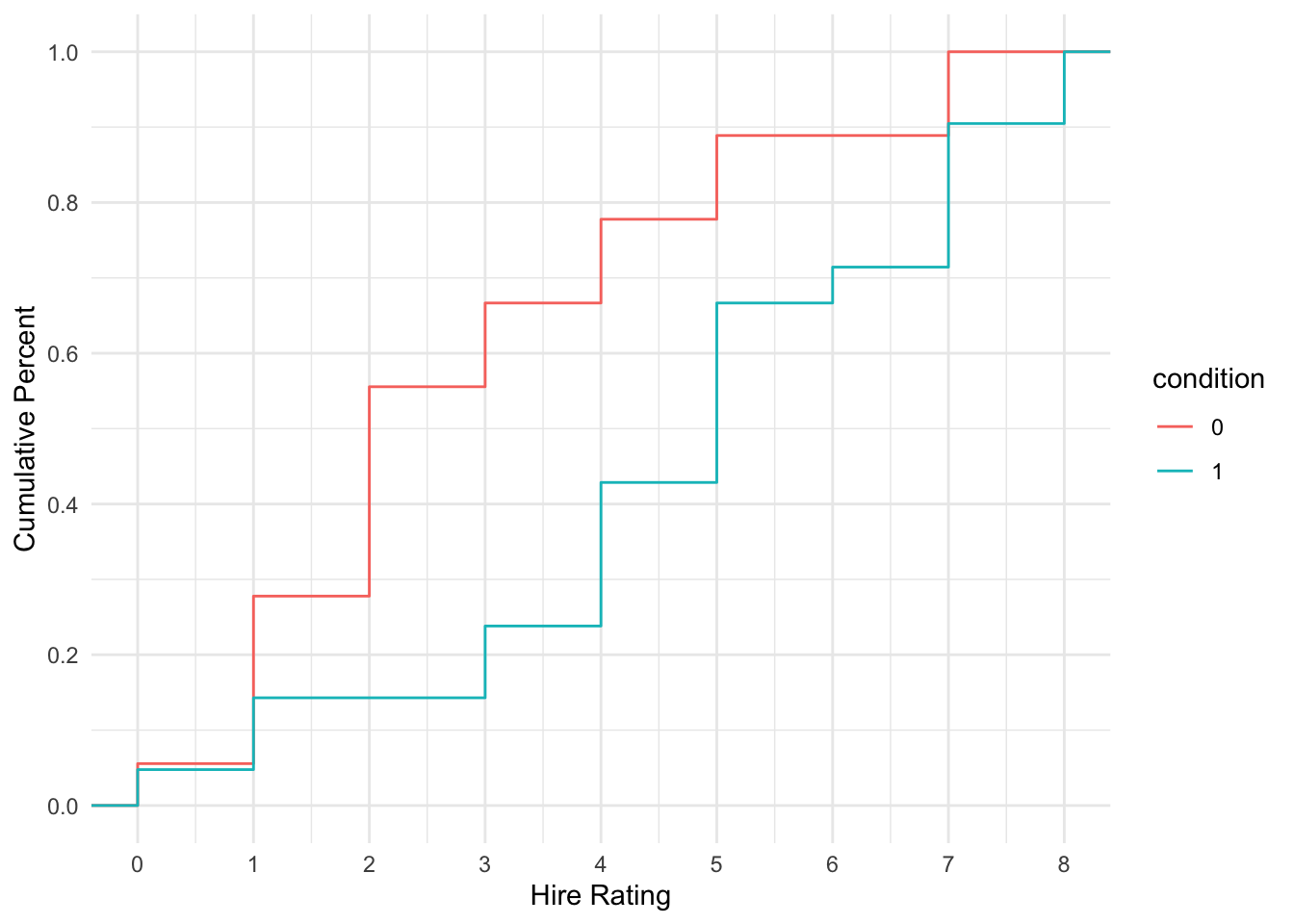
Finally, we can fit our ordinal regression model and see the slope coefficient is positive and it is statistically significant.
formula: hire_factor ~ condition
data: schroeder_data
link threshold nobs logLik AIC niter max.grad cond.H
logit flexible 39 -77.29 172.59 7(1) 5.69e-10 1.6e+02
Coefficients:
Estimate Std. Error z value Pr(>|z|)
condition1 1.5409 0.6146 2.507 0.0122 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Threshold coefficients:
Estimate Std. Error z value
0|1 -2.364790 0.754794 -3.133
1|2 -0.761366 0.459091 -1.658
2|3 -0.009953 0.437700 -0.023
3|4 0.526688 0.459758 1.146
4|5 1.262387 0.504261 2.503
5|6 2.197283 0.575101 3.821
6|7 2.357000 0.589496 3.998
7|8 3.976969 0.861277 4.618 2.5 % 97.5 %
condition1 0.3669235 2.791582To be easier to interpret, we can convert the log odds to the odds ratio by taking the exponential for the slope coefficient and its 95% confidence interval.
condition1
4.668953 2.5 % 97.5 %
condition1 1.443288 16.3068Finally, as a demonstration, we can calculate the estimated cumulative probability of choosing a rating of less than 3 (0-2) for the transcript group and the audio group. Note we are using coefficient 3 as that is the third threshold. We then subtract coefficient 9 as the slope coefficient is added on to the end.
# Cumulative percentage for transcript group choosing less than 3 - coefficient 1
exp(coef(schroeder_model2)[3]) / (1 + exp(coef(schroeder_model2)[3])) 2|3
0.4975119 # Cumulative percentage for audio group choosing less than 3 - coefficient 1 minus coefficient 9
exp(coef(schroeder_model2)[3] - coef(schroeder_model2)[9]) / (1 + exp(coef(schroeder_model2)[3] - coef(schroeder_model2)[9])) 2|3
0.1749581