Scraping and Visualising Twitter Data


The slides - this page includes the same information, but you might prefer to follow along with the slides.
Packages
This section loads the rtweet, tidytext, ggpubr and the tidyverse packages.
library(rtweet)
library(tidytext)
library(ggpubr)
library(tidyverse) Introduction
In the previous sessions, we have already had some practice with ggplot2 and with tidytext. Now we are going to learn how to scrape data from Twitter with the rtweet package and use this in conjunction with our new text wrangling skills. All that is needed is a Twitter account, and we are good to go.
- After loading the rtweet package, you will need to open up Twitter in your browser for the authentication process (allowing RStudio to interact with Twitter’s API).
rtweetwill only work via a desktop RStudio connection, and won’t work if you run it in for example RStudio Cloud or via a server connection.
We can get the entire timeline of any Twitter user (including yourself). One of my most favorite Twitter accounts is the Lego Grad Student, who chronicles his struggles as an early career researcher in tweets and pictures.
Download tweets
We can download up to 3200 of lego grad student’s most recent tweets.
# Download all recent tweets of account
lego<- get_timeline("@legogradstudent", n=3200)Let’s have a look at the dataframe. You can use view(lego) or click on the lego object in the environment.
# Look at the dataframe
view(lego)Take a moment to explore this dataframe, have a look at what kind of variables there are and which ones might be interesting to explore later on. If you want to get a quick overview of a dataframe you can use head(), which returns the first few rows and tells you how many variables there are in total.
# get first few rows
head(lego)## # A tibble: 6 x 88
## user_id status_id created_at screen_name text source
## <chr> <chr> <dttm> <chr> <chr> <chr>
## 1 744046… 11393616… 2019-06-14 02:39:08 legogradst… @nan… Twitt…
## 2 744046… 11392144… 2019-06-13 16:54:16 legogradst… Havi… Twitt…
## 3 744046… 11363349… 2019-06-05 18:12:09 legogradst… @Gae… Twitt…
## 4 744046… 11363116… 2019-06-05 16:39:39 legogradst… "One… Twitt…
## 5 744046… 11353079… 2019-06-02 22:11:13 legogradst… @sch… Twitt…
## 6 744046… 11352772… 2019-06-02 20:09:32 legogradst… "@da… Twitt…
## # … with 82 more variables: display_text_width <dbl>,
## # reply_to_status_id <chr>, reply_to_user_id <chr>,
## # reply_to_screen_name <chr>, is_quote <lgl>, is_retweet <lgl>,
## # favorite_count <int>, retweet_count <int>, hashtags <list>,
## # symbols <list>, urls_url <list>, urls_t.co <list>,
## # urls_expanded_url <list>, media_url <list>, media_t.co <list>,
## # media_expanded_url <list>, media_type <list>, ext_media_url <list>,
## # ext_media_t.co <list>, ext_media_expanded_url <list>,
## # ext_media_type <chr>, mentions_user_id <list>,
## # mentions_screen_name <list>, lang <chr>, quoted_status_id <chr>,
## # quoted_text <chr>, quoted_created_at <dttm>, quoted_source <chr>,
## # quoted_favorite_count <int>, quoted_retweet_count <int>,
## # quoted_user_id <chr>, quoted_screen_name <chr>, quoted_name <chr>,
## # quoted_followers_count <int>, quoted_friends_count <int>,
## # quoted_statuses_count <int>, quoted_location <chr>,
## # quoted_description <chr>, quoted_verified <lgl>,
## # retweet_status_id <chr>, retweet_text <chr>,
## # retweet_created_at <dttm>, retweet_source <chr>,
## # retweet_favorite_count <int>, retweet_retweet_count <int>,
## # retweet_user_id <chr>, retweet_screen_name <chr>, retweet_name <chr>,
## # retweet_followers_count <int>, retweet_friends_count <int>,
## # retweet_statuses_count <int>, retweet_location <chr>,
## # retweet_description <chr>, retweet_verified <lgl>, place_url <chr>,
## # place_name <chr>, place_full_name <chr>, place_type <chr>,
## # country <chr>, country_code <chr>, geo_coords <list>,
## # coords_coords <list>, bbox_coords <list>, status_url <chr>,
## # name <chr>, location <chr>, description <chr>, url <chr>,
## # protected <lgl>, followers_count <int>, friends_count <int>,
## # listed_count <int>, statuses_count <int>, favourites_count <int>,
## # account_created_at <dttm>, verified <lgl>, profile_url <chr>,
## # profile_expanded_url <chr>, account_lang <lgl>,
## # profile_banner_url <chr>, profile_background_url <chr>,
## # profile_image_url <chr>Tidy tweets
We see that 88 variables were imported. We want to select only variables (=columns), that we are interested in at the moment. The column we are most interested in is lego$text. This column contains the actual tweets. Then we need to make the data tidy, e.g. restructure it into a long format (one word per row).
# We need to restructure lego as one-token-per-row format
tidy_tweets <- lego %>% # pipe data frame
filter(is_retweet==FALSE)%>% # only include original tweets
select(status_id,
text)%>% # select variables of interest
unnest_tokens(word, text) # splits column in one token per row formatCheck if it worked:
view(tidy_tweets)Stop words
When we process text, we filter out the most common words in a language. These are called stop words (for example “the”, “is” and “at”).
stop_words| word | lexicon |
|---|---|
| a | SMART |
| a’s | SMART |
| able | SMART |
| about | SMART |
| above | SMART |
| according | SMART |
Here we define our own custom stopwords. These are specific to dealing with internet data. We want to filter out everything referencing websites and URLs. We use the tibble() function to construct a dataframe containing our custom internet stop words and define the name of our lexicon. You can amend this if you want to insert for example additional stop words that you have found by exploring the tidy_tweets dataframe.
my_stop_words <- tibble( #construct a dataframe
word = c(
"https",
"t.co",
"rt",
"amp",
"rstats",
"gt"
),
lexicon = "twitter"
)| word | lexicon |
|---|---|
| https | |
| t.co | |
| rt | |
| amp | |
| rstats | |
| gt |
Now we connect our custom Internet stop words with the stop words library included in tidytext and filter out any numbers. We are using bind_rows() to connext the two dataframes, which means the columns will be matched by name and our custom stop words will be added at the end of the included stop word lexicon.
# Connect stop words
all_stop_words <- stop_words %>%
bind_rows(my_stop_words) # here we are connecting two data frames
# Let's see if it worked
view(all_stop_words)
# Remove numbers
no_numbers <- tidy_tweets %>%
filter(is.na(as.numeric(word))) # remember filter() returns rows where conditions are true## Warning: NAs introduced by coercionDon’t worry about the warning message you are receiving here, the as.numeric function gives a warning when it tries to turn non-number words into numbers, which is what we are looking to do here. The warnings we receive from R should be read for meaning. They can be useful clues as to why you are stuck. You can use the help function in R (?as.numeric()) or google the error message if you are unsure what is going on.
Now we get rid of the combined stop words by using anti_join(). We used this already in one of the previous sessions, but if you are unsure about what anti_join() does you can read more about it here or call the help function in the R console ?anti_join().
no_stop_words <- no_numbers %>%
anti_join(all_stop_words, by = "word")We started with 58610 words and are now left with 21092 words. Over half the tweeted words turned out to be stop words. Removing the stop words is important for later visualization and the sentiment analysis - we only want to plot and analyze the ‘interesting’ tweets.
Sentiment analysis
One form of text analysis that is particularly interesting for Twitter data is sentiment analysis. With the help of lexica we can find a sentiment (emotional content) for each tweeted word and then have a closer look at the emotional content of the tweets.
Let’s first have a look at the lexicon we will be using: nrc.
nrc <- get_sentiments("nrc") # get specific sentiment lexicons in a tidy formatHave a look at the dataframe by using either view(nrc) or by clicking on the object in the environment on the right hand side.
view(nrc)Now we want to add find out the sentiments (=emotional content) for each word in our dataframe no_stop_words. To do that, we can use the inner_join function, which returns all the rows that have a match in the other table.
nrc_words <- no_stop_words %>%
inner_join(nrc, by="word")
view(nrc_words)Visualization
Now that we have shaped our text data into tidy form and figured out the emotional content of the tweeted words, we can plot this information to find out at one glance if the timeline of Lego Grad Student is more positive or negative, and which emotions prevail.
pie_words<- nrc_words %>%
group_by(sentiment) %>% # group by sentiment type
tally %>% # counts number of rows
arrange(desc(n)) # arrange sentiments in descending order based on frequencyNow let’s plot! We use the ggpubr package, which gives us easy-to-use functions for creating and customizing ‘ggplot2’- based plots. One option to visualize the emotional content of the tweets is by using a pie chart.
ggpubr::ggpie(pie_words, "n", label = "sentiment",
fill = "sentiment", color = "white",
palette = "Spectral")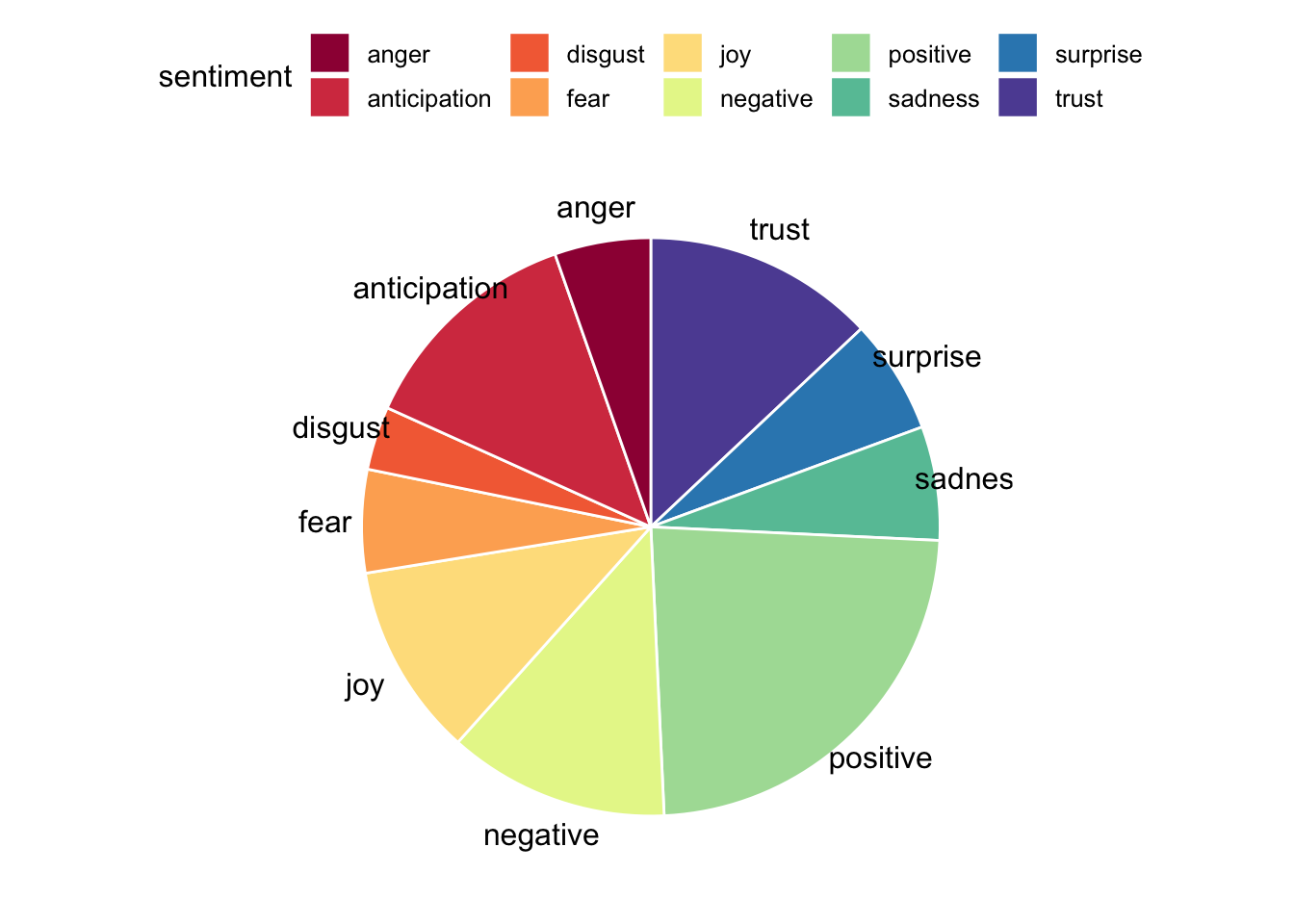
If you’ve already finished the main part of this tutorial, you can move on to these additional exercises, where you can practice plotting wordclouds, learn how to render emojis in R Markdown and search for specific hashtags on Twitter.
Exercises
Plot a tweet wordcloud!
With wordclouds we can easily visualize which words were most frequently tweeted by the Lego Grad Student. Try to visualize the top 50 words and set the maximum text size to 26. You’ll need the ggwordcloud package.
Note: if the words look a bit jumbled in your plot window, open the larger plot window with ‘zoom’.
First we count how many times each word was tweeted.
words_count<- no_stop_words %>%
dplyr::count(word, sort = TRUE) # count number of occurencesHow to plot the wordcloud?
Show Solution…
library(ggwordcloud) # we need to load the ggwordcloud package
set.seed(42)
wordcloudplot<- head(words_count, 50)%>% #select first 50 rows
ggplot(aes(label = word, size = n, color = word, replace = TRUE)) + # start building your plot
geom_text_wordcloud_area() + # add wordcloud geom
scale_size_area(max_size = 26) + # specify text size
theme_minimal() # choose theme
wordcloudplot # show word cloud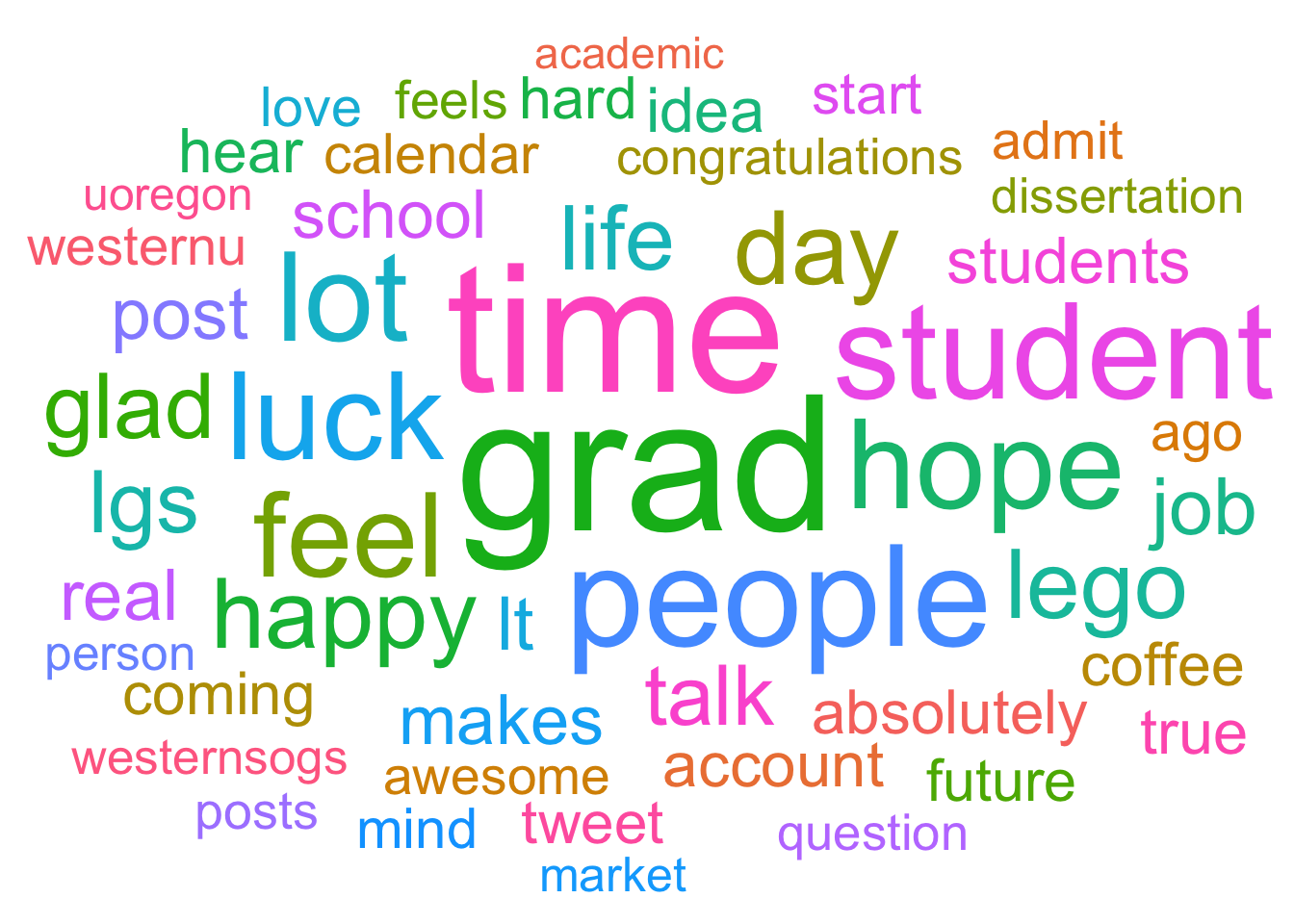
If you want to save the wordcloud, click on export, then save as image and remember to set the desired width and height. If you are not happy with the look of your wordcloud, you can have a look at the tutorial by E. Le Pennec.
Emojis
IMPORTANT NOTE: Through some trouble shooting we have noticed that there are some issues with rendering emojis on Windows machines. The below steps will only render the emojis if running R on a Mac (or possibly Linux).
Installing packages.
#### Getting the devtools package - uncomment below code to run ####
# install.packages("devtools")
library(devtools)
#### Getting the emo package - uncomment below code to run ####
# devtools::install_github("hadley/emo")
library(emo)With the emo package we can render emojis in R Markdown!
emo::ji("robot")## 🤖emo::ji("heart")## ❤️emo::ji("smile")## 😄emo::ji("ghost")## 👻You can try out in the console if you can render your favorite emoji!
Let’s see if we can find out which emojis the Lego Grad Student uses most often. To do that we can use an emo function called ji_extract_all.
emoji <- lego %>%
mutate( # add a column, call it emo, and insert all the emojis we can extract from the text column
emo = ji_extract_all(text)
) %>%
select(created_at,emo) %>% # select the data the tweet was posted and the emoji column
unnest(emo) # unnest a list column
emoji## # A tibble: 7 x 2
## created_at emo
## <dttm> <chr>
## 1 2018-08-24 02:54:55 😃
## 2 2018-07-18 02:32:23 🏳️
## 3 2018-03-30 18:04:39 😀
## 4 2017-09-23 01:39:53 😢
## 5 2017-09-23 01:39:53 😥
## 6 2017-09-23 01:39:53 😪
## 7 2017-08-28 06:52:50 😳It looks like the Lego Grad Student barely uses emojis in his tweets. You can scrape your own Twitter timeline and repeat the above code to see what emojis you use and which ones are your favorite ones.
Conclusion
R offers us lots of fun ways to obtain some interesting data from Twitter, wrangle it and visualize using beautiful plots. If after this workshop you end up making some nice plots with rtweet, tag me and let me know how it goes!
Resources
- Learn more about
tidytextthrough Julia Silge’s and David Robinson’s tutorial. - Comprehensive
tidytextbook (includes a chapter on sentiment analysis): Tidy Text Mining with R by Julia Silge and David Robinson - More functions included in
rtweetcan be found via this tutorial by Michael W. Kearney. - Sentiment analysis tutorial by Edgar’s Data Lab