4 Error checking and debugging
In this chapter, you’ll learn how to use AI to identify and fix coding errors. This is probably the best use case of AI: using it to debug code that you wrote. Human expertise drives the code, while AI’s attention to detail can help spot small mistakes such as missing commas.
AI is generally good at this task, although the more complex your code, the more likely it is to struggle. This chapter gives examples to help you with prompt engineering for error checking.
So that you can reproduce the same errors, let’s create a reproducible example and load some packages and a dataset.
Open a new Quarto or Rmd document and create a new code chunk. Run the code below to load packages and a dataset. You may need to install the package palmerpenguins if you do not already have it.
4.1 Simple errors
Unlike the other chapters you don’t need to do any set-up, in fact, you can often just copy and paste the code and error in and it will figure out that you want it to fix it without even needing to explicitly ask.
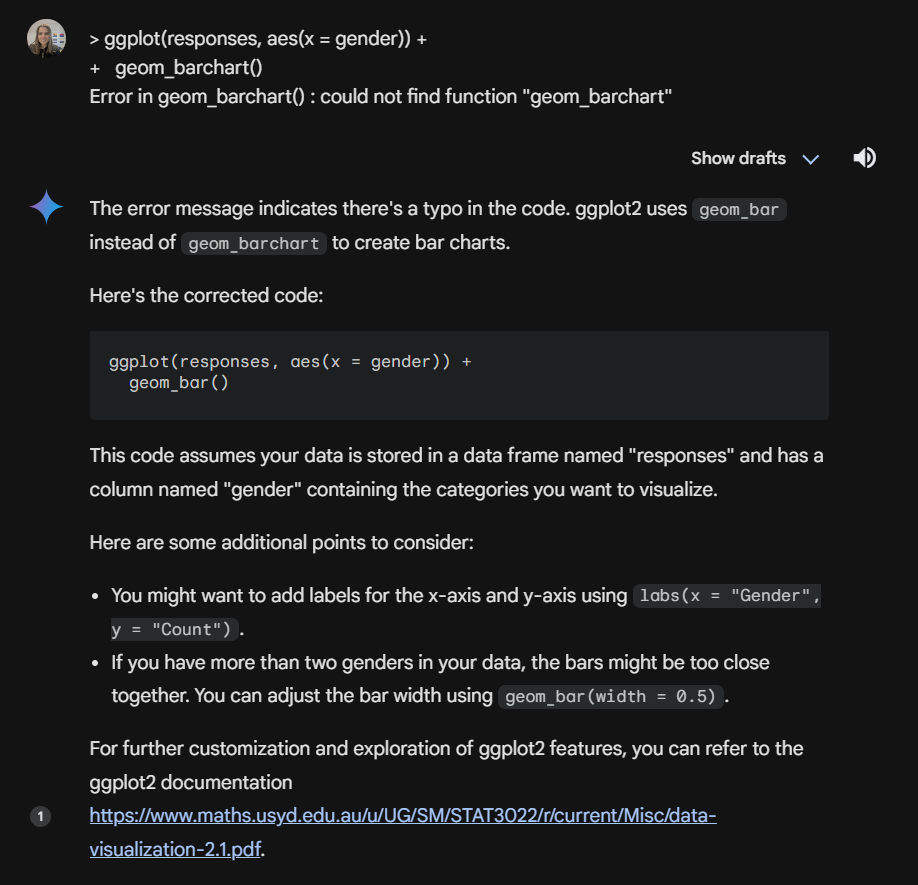
Here’s a simple error where we have given it the wrong function name:
Error in geom_barchart(): could not find function "geom_barchart"Give Copilot both the code and the error. One without the other is likely to result in a poor or incomplete answer (whether you ask a human or an AI).
4.2 Contextual errors
A common issue is when the error stems from code earlier in your script, even though it shows up later.
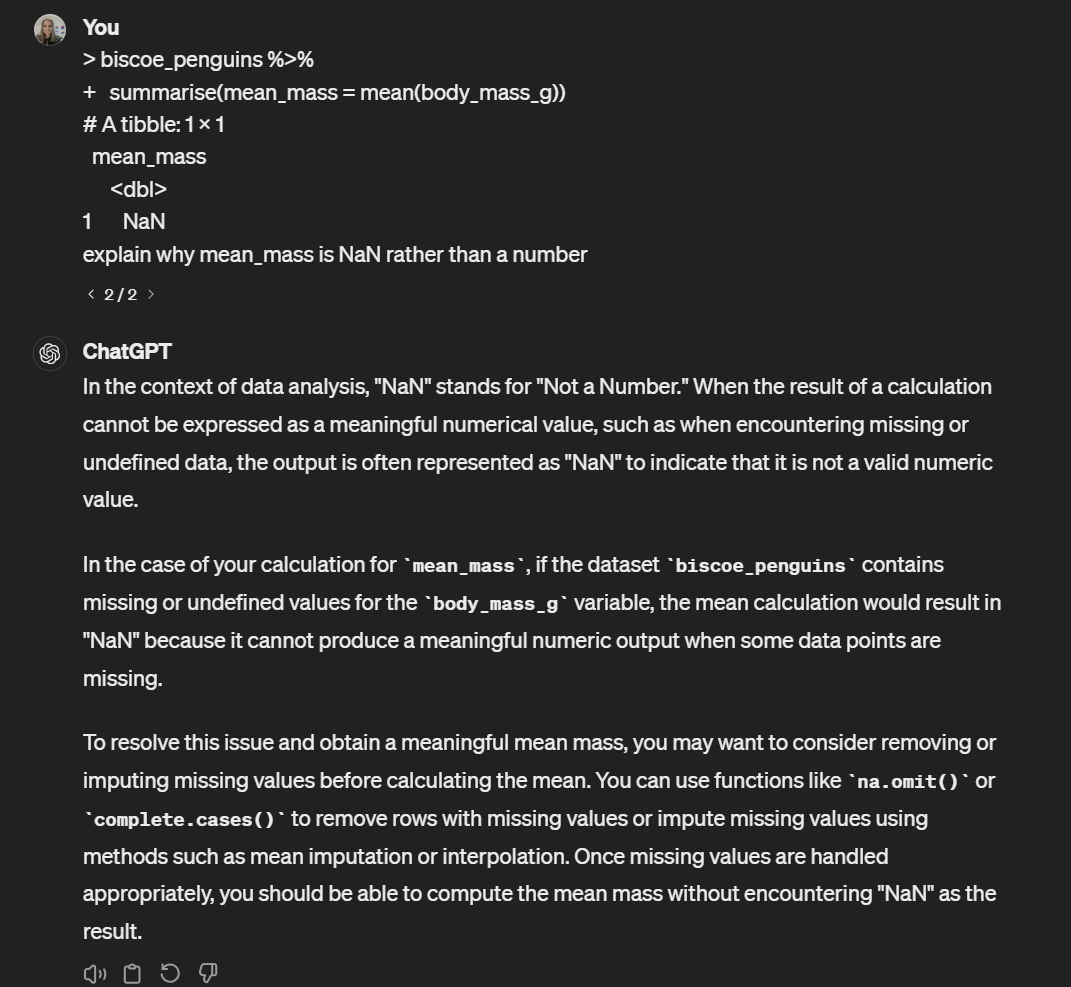
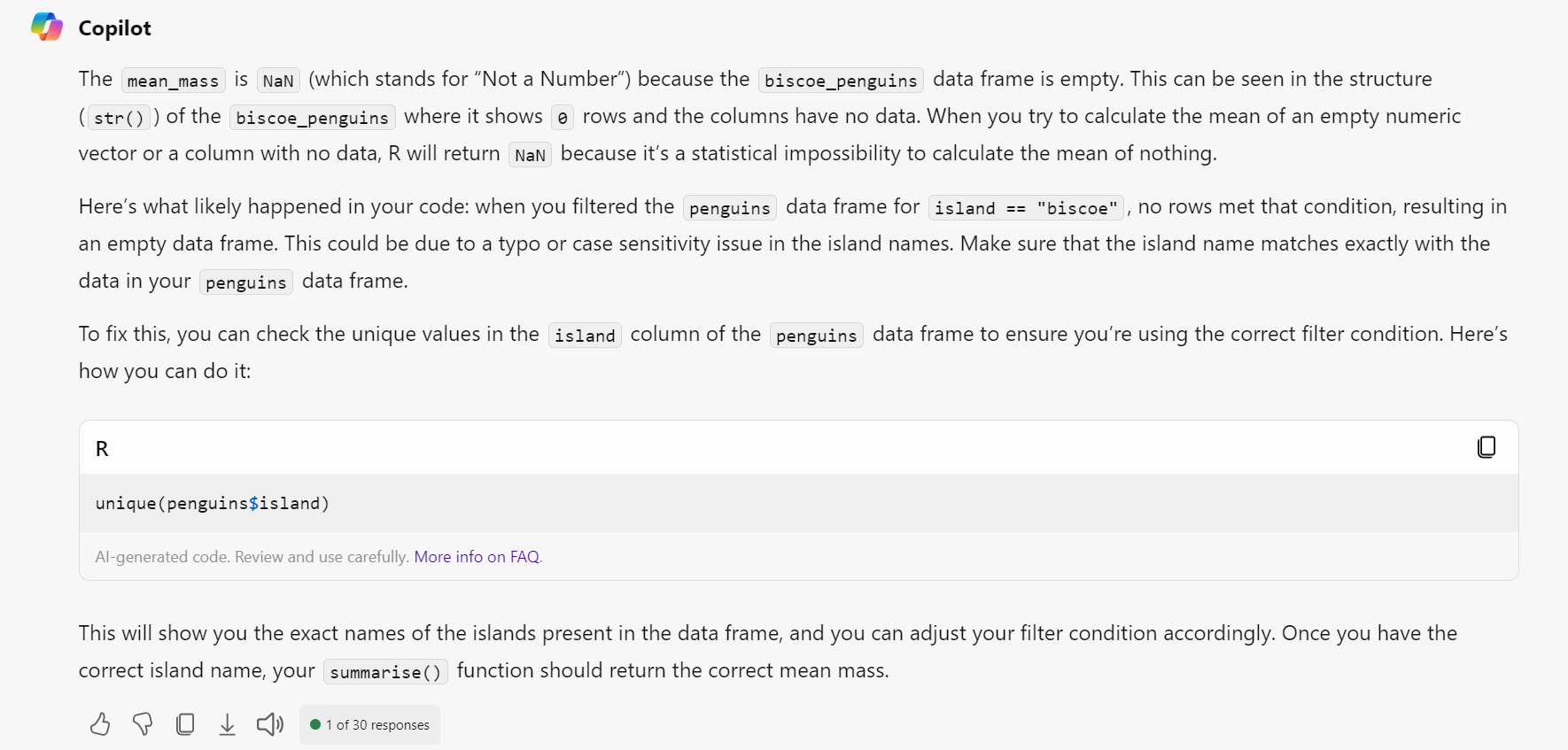
For example, in this code, what we intended to do was to create a dataset that just has penguins from Biscoe Island and then calculate their mean body mass. This code will run, but it produces NaN as the value.
biscoe_penguins <- penguins %>%
filter(island == "biscoe")
biscoe_penguins %>%
summarise(mean_mass = mean(body_mass_g))| mean_mass |
|---|
| NaN |
If you just give an AI the code and the table and ask it to explain what’s happening, it will do its best but without knowing the dataset or what code has preceded it, it won’t give you the exact answer, although in this case it hints at it.
There’s a couple of things you can do at this point:
- Give the AI all the code you’ve used so far
- Give the AI more information about the dataset.
You can manually type out a description but there’s some functions you can use that can automate this.
summary() is useful because it provides a list of all variables with some descriptive statistics so that the AI has a sense of the type and range of data:
species island bill_length_mm bill_depth_mm
Adelie :152 Biscoe :168 Min. :32.10 Min. :13.10
Chinstrap: 68 Dream :124 1st Qu.:39.23 1st Qu.:15.60
Gentoo :124 Torgersen: 52 Median :44.45 Median :17.30
Mean :43.92 Mean :17.15
3rd Qu.:48.50 3rd Qu.:18.70
Max. :59.60 Max. :21.50
NA's :2 NA's :2
flipper_length_mm body_mass_g sex year
Min. :172.0 Min. :2700 female:165 Min. :2007
1st Qu.:190.0 1st Qu.:3550 male :168 1st Qu.:2007
Median :197.0 Median :4050 NA's : 11 Median :2008
Mean :200.9 Mean :4202 Mean :2008
3rd Qu.:213.0 3rd Qu.:4750 3rd Qu.:2009
Max. :231.0 Max. :6300 Max. :2009
NA's :2 NA's :2 str() is also useful because it lists the variables, their data type, and the initial values for each variable.
tibble [344 × 8] (S3: tbl_df/tbl/data.frame)
$ species : Factor w/ 3 levels "Adelie","Chinstrap",..: 1 1 1 1 1 1 1 1 1 1 ...
$ island : Factor w/ 3 levels "Biscoe","Dream",..: 3 3 3 3 3 3 3 3 3 3 ...
$ bill_length_mm : num [1:344] 39.1 39.5 40.3 NA 36.7 39.3 38.9 39.2 34.1 42 ...
$ bill_depth_mm : num [1:344] 18.7 17.4 18 NA 19.3 20.6 17.8 19.6 18.1 20.2 ...
$ flipper_length_mm: int [1:344] 181 186 195 NA 193 190 181 195 193 190 ...
$ body_mass_g : int [1:344] 3750 3800 3250 NA 3450 3650 3625 4675 3475 4250 ...
$ sex : Factor w/ 2 levels "female","male": 2 1 1 NA 1 2 1 2 NA NA ...
$ year : int [1:344] 2007 2007 2007 2007 2007 2007 2007 2007 2007 2007 ...Finally, ls() provides a list of all the variables in a given object. It doesn’t provide any info on the variable type or sample, but this might be all the info you really need to give the AI.
[1] "bill_depth_mm" "bill_length_mm" "body_mass_g"
[4] "flipper_length_mm" "island" "sex"
[7] "species" "year" Be careful with sensitive data. str() and summary() reveal actual data values, so only use them if your data management plan permits it. Using Copilot Enterprise reduces (but does not remove) risk, since data is not used for model training. Start with ls(), which only lists variable names, and scale up if safe.
Run summary(biscoe_penguins) and give the AI the output so that it better understands the structure and contents of the datasets.
Then give it the code you used to filter the dataset.
If you haven’t spotted it by now, the error is that in the filter biscoe should be Biscoe with a capital B.
There is no shortcut for knowing your data.
4.3 Incorrect (but functional) code
Sometimes (often) when we write code, the issue isn’t that our code doesn’t work, but that it doesn’t do what we intended to do and we can’t figure out why.
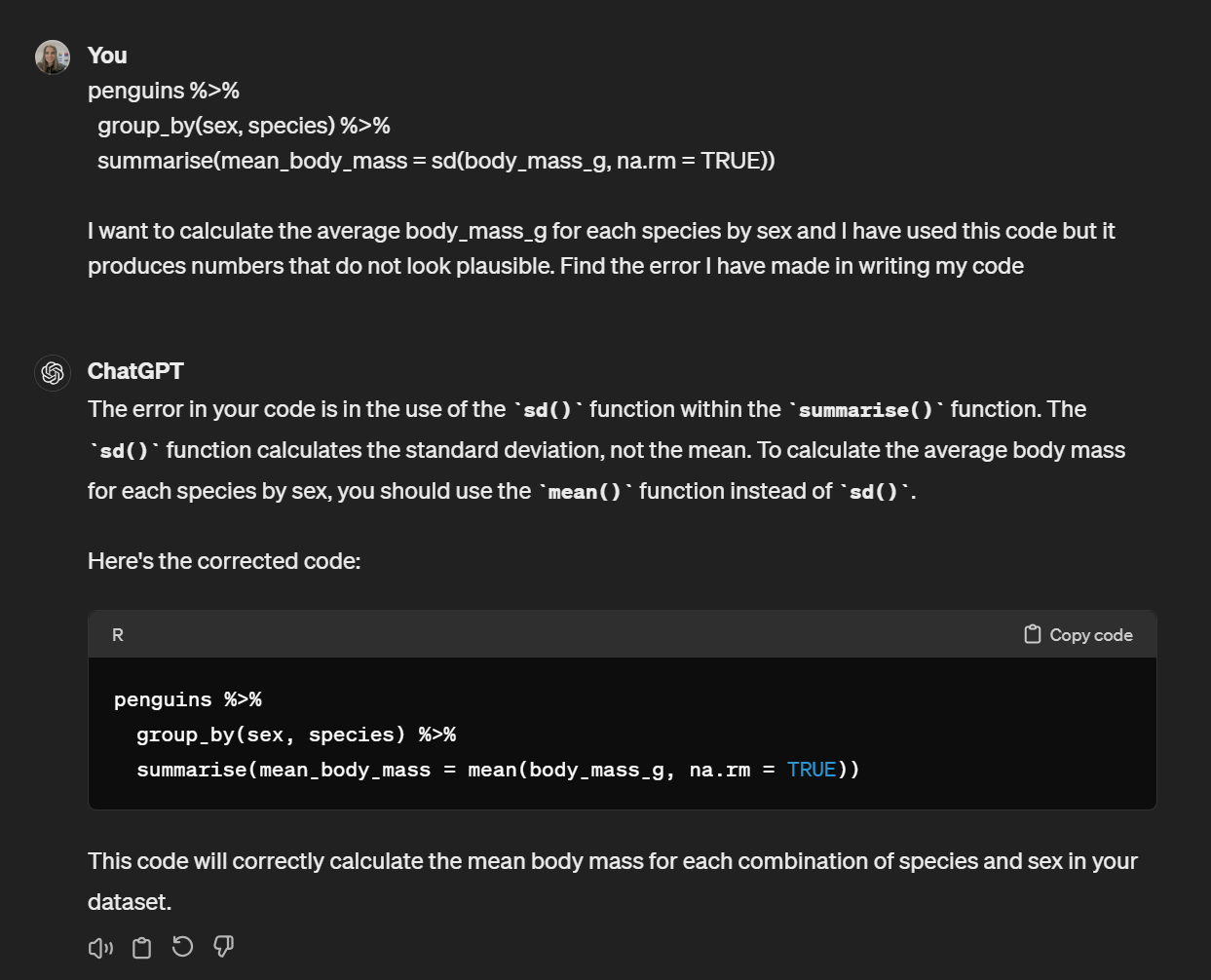
For example, let’s say that we want to calculate the average body_mass_g for each species by sex. We’re feeling a bit lazy and we copy and paste in the following from a previous script we have:
| sex | species | mean_body_mass |
|---|---|---|
| female | Adelie | 269.3801 |
| female | Chinstrap | 285.3339 |
| female | Gentoo | 281.5783 |
| male | Adelie | 346.8116 |
| male | Chinstrap | 362.1376 |
| male | Gentoo | 313.1586 |
| NA | Adelie | 477.1661 |
| NA | Gentoo | 338.1937 |
We know something isn’t right here. Because we’re responsible researchers, we’ve taken time to understand our dataset and what plausible values should be and we know there’s no way that the average body mass of a penguin is 269 grams (unless the penguin is made of chocolate). But the code is running fine, we know it’s worked before, and we can’t see what we’ve done wrong.
You can ask the AI to help you but you can’t just give it the code and output, you also need to tell it what you intended to do. The more complex your code, the more information you will need to give it in order for it to help you find the error.
There is no AI tool that allows you to skip understanding the data you’re working with and knowing what it is you’re trying to do.
4.4 Document errors
If you’re working in Rmd or Quarto, sometimes the errors will stem from your code chunk settings or YAML in the document.
The code is fine, it provides a simple count of the number of observations in the dataset. But if you try and knit the file in Rmd you’ll get a very long error message and if you render the file in Quarto, it will work, but it won’t actually execute the code, it will just render it as text.
In these cases you have two options.
Copy and paste the entire document into Copilot, not just the code but include the code chunks etc. This means it can see the formatting as well as the code.
Take a screenshot. This can also sometimes help diagnose working directory issues if you include the files pane.
If you’re not at all sure where the issue is stemming from, you might need a combination of both. But whatever you do, make sure that you verify the explanation of the error, don’t trust it blindly.
Try pasting the entire document into Copilot and/or providing a screenshot until it can diagnose the missing backtick.
I know I might be starting to sound like a broken record but please remember that artificial intelligence is not actually intelligent. It’s not thinking, it’s not making conscious decisions, it has no expert subject matter knowledge. No matter how helpful it is, you must always check the output of the code it gives you.
4.5 Common errors
Coding errors tend to repeat and there’s actually a fairly small set of errors you will make constantly. But you won’t learn these patterns if you always ask the AI.
- Missing or extra ()
- Missing or extra commas
- Missing or extra quotation marks
- Typos in object or variable names - remember R is case sensitive
- Missing
+for ggplot() - Missing
|>or%>%for piped lines of code - Using
=instead of== - Writing code but not running it so that e.g., a package isn’t loaded or an object isn’t created that you later need.
- Trying to perform a numerical operation on a character/factor variable (or vice versa).
To help boost your confidence in error checking and debugging, you can create Error Mode questions like we showed you in Chapter 3. You could ask it to give you examples based on the common list of errors noted above and work your way through them until you’re more comfortable spotting them in your own code.
4.6 Be critical
From a cognitive science perspective, being critical when debugging with AI matters because learning is strongest when you engage in active processing rather than relying on external answers. Research on desirable difficulties shows that struggling with a problem, even briefly, improves long-term retention and transfer. Similarly, studies of self-explanation demonstrate that learners build deeper understanding when they articulate why an error occurred and how to fix it. If you immediately outsource error checking to AI, you bypass the very processes that consolidate your knowledge of syntax, functions, and debugging strategies.
Another benefit of practising debugging yourself before turning to AI, is the development of self-efficacy and autonomy. In Bandura’s terms, mastery experiences are the strongest source of self-efficacy: each time you locate and fix an error unaided, you build the expectation that you can do so again.
Autonomy is likewise enhanced when you make choices about how to proceed rather than defaulting to external solutions. Framed through self-determination theory, brief, well-timed AI support can still help, provided it is autonomy-supportive (you decide when to ask), competence-supportive (it explains rather than replaces your reasoning), and scaffolded (assistance fades as you improve).
In practice: attempt a fix first, articulate a hypothesis about the bug, then use AI to test or refine that hypothesis. This preserves a sense of authorship over your code, strengthens future problem-solving, and reduces learned dependence on external help.
Try first, then ask AI. Read the error message, inspect recent edits, and attempt a fix before consulting AI. This strengthens understanding and builds self-efficacy.
Provide full context. When you do use AI, include the code and the exact error message. Add brief intent (“what I meant to do”) and, if safe, a minimal reproducible example.
Know your data. Many “mystery” errors are case sensitivity, misspellings, or filtering mistakes. Use
summary(),str(), orls()to verify assumptions.Protect sensitive data. Prefer
ls()first; only sharesummary()/str()outputs if your data management plan permits. Copilot Enterprise reduces but does not remove risk.Expect and learn common patterns in errors.
State the goal. Tell AI what outcome you intended (e.g., “mean by species and sex”), not just the code, to help it detect functional (not just syntactic) errors.
Use screenshots or full documents for format bugs. For Rmd/Qmd issues, share the whole document or a screenshot showing YAML, chunk fences, and working directory.
Treat AI as scaffolding. Ask it to explain rather than replace reasoning, and fade assistance over time to preserve autonomy and develop durable debugging habits.