5 Code review
In this chapter you’ll learn how to use AI to perform a code review and to add comments to your code. As you’ve already hopefully learned by working through this book, you have to be critical about anything the AI produces or suggests because it has no expert knowledge, but it can be a useful tool for checking and improving your code.
DeBruine et al’s Code Check Guide details what a comprehensive code check refers to:
- Does it run? Can a researcher who uses that progamming language run it easily? Are any unusual or complex procedures explained?
- Is it reproducible? Do you get the same outputs? Is it straightforward to check them?
- Is it auditable/understandable? Even if you don’t have the expertise to assess the stats or data processing, is the code well-organised enough to figure out what is intended so mistakes could be detected? Are the outputs sufficiently detailed to allow interrogation?
- Does it follow best practices? Is there too much repeated code that could benefit from modularisation? DRY (Don’t repeat yourself) and SPOT (Single Point of Truth)? Are the outputs of long processes saved and loaded from file? Do the variable names make sense? Do the results match what is shown in the output and there is no rounding up or down?
- Is it correct and appropriate? Is the code actually doing what is intended? Is what is intended correct? Some logical problems can be caught without domain knowledge, such as intending to to filter out male subjects, but actually filtering them IN. Many other problems require domain and/or statistical knowledge, so may only be appropriate in some circumstances.
However, some of these steps cannot (and should not) be performed by an AI. Unless you have specific ethical approval and have included this in your data management plan, you should never upload your research data to an AI tool. This means that assessing reproducibility is difficult. The AI also doesn’t know what you intended to do, and why, and has no subject knowledge so it can’t advise on anything theoretical without you giving it that information explicitly.
Therefore, what we’ll focus on in this chapter is two components of code review: comments and refactoring your code.
5.1 Code comments
Code comments are lines or sections of text added within the code itself that are ignored by the computer when the program runs. They’re there for human readers, not machines. In R, you add comments to code by adding # to the start of the string:
Comments are useful for several reasons:
- Clarification: They explain what certain parts of the code do, making it easier for others (and yourself) to understand the logic and flow of the code.
- Documentation: They provide information on how the code works or why certain decisions were made, which is helpful for future reference.
- Debugging: Temporarily commenting out parts of code can help isolate sections that may be causing errors, without deleting the code.
- Collaboration: In team projects, comments can be used to communicate with other developers about the status or purpose of the code.
Overall, comments are a crucial part of writing clean, maintainable, and collaborative code. They help make the code more accessible and understandable to anyone who might work on it in the future.
5.2 Adding comments with AI
First we’ll use use the palmerpenguins dataset again.
You can use AI tools to help add comments to your code. Previous experience has taught us that we need to be a bit specific with what we want the AI to do so we’ll give it a clear prompt.
For this chapter, be very, very careful to ensure you are using GPT-5, not GPT-4. The performance of GPT-5 is significantly better and avoids introducing errors into your code.
In Copilot, input the below code with the prompt:
Please add concise, helpful comments to this code. Explain what each main step does, not every line. If you are unsure about what a section of code is doing or why it exists, ask me a clarifying question. Do not change the code itself in any way.
Here’s its suggested comments:
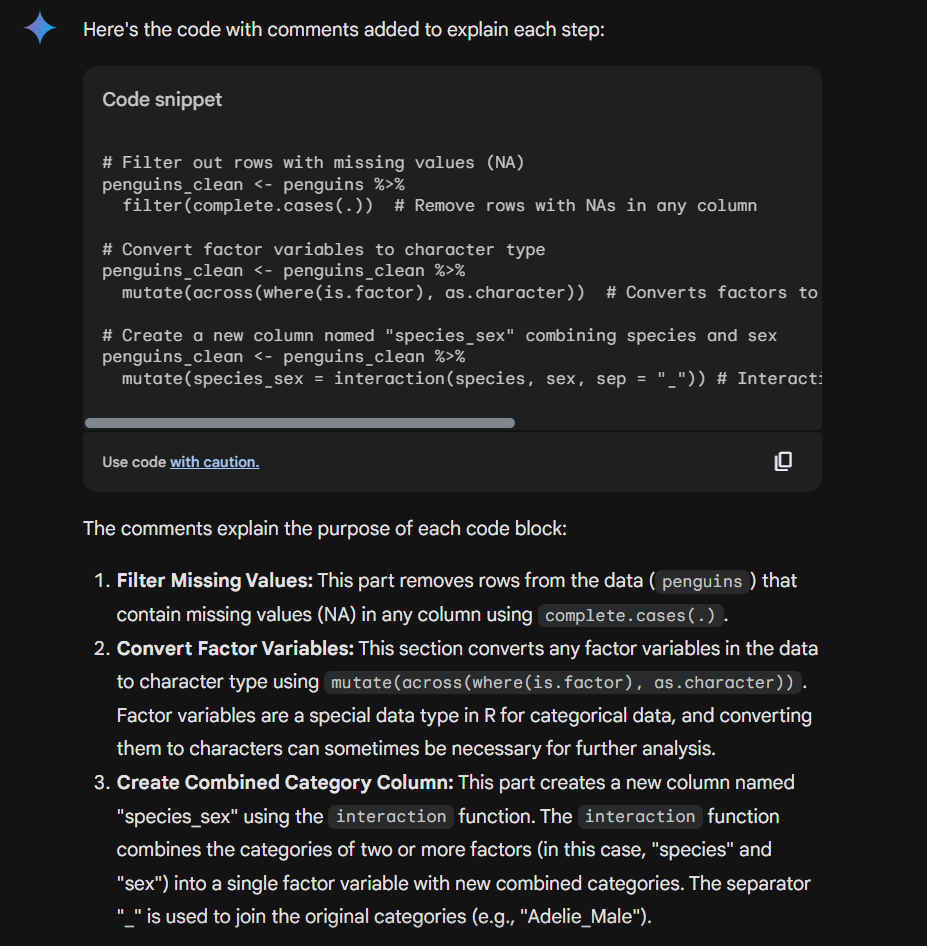
# Clean data, convert factors to character, and create a combined label
penguins_clean <- penguins %>% # start from the penguins data
filter(complete.cases(.)) %>% # keep only rows with no missing values in any column
mutate(across(where(is.factor), as.character)) %>%# convert all factor columns to character
mutate(species_sex = interaction(species, sex, sep = "_")) # new factor combining species and sex, e.g., "Adelie_female"However, the AI can only tell you what the code is doing, it can’t say why you chose to do that. The more complex your analysis, the more crucial it becomes to explain the rationale and so ensuring your prompt encourages the AI to ask for clarification is vital and in order to be able to answer these questions you need to know your data and what you’re trying to achieve.
5.3 Review existing comments
In addition to asking AI to comment your code, you can also ask it to review comments you’ve made yourself. To see how this works with a more complex example, and as an act of masochism, I gave the AI some code I wrote for a publication. The full paper is here if you’re interested - the quant analyses ended up being punted to the online appendix because of word count.
The first section of my code involves quite a complicated and long bit of wrangling, all done in a single pipeline. The purpose of the code is to clean up data collected on the survey platform Qualtrics and recode some of the demographic variables. This is actually a shortened version because the original hit the character limit for Copilot. I did put some effort into writing comments before publication but there are almost certainly improvements to be made.
Provide the code with the following prompt followed by the below code:
Please review the comments in my code and improve them where needed. Make comments clear, concise, and useful for someone reading the code for the first time. Keep the meaning of existing comments, but reword or simplify them for better readability.
Add comments only where they genuinely help understanding (e.g., explaining intent or logic, not obvious code). Do not change any of the code itself. After editing, explain your reasoning for each change — briefly describe why the original comment needed improvement (e.g., too long, unclear, redundant, missing context, etc.).
dat <- dat_raw%>%
filter(Progress > 94, # remove incomplete responses
DistributionChannel != "preview") %>% # Remove Emily's preview data
select(ResponseId, "duration" = 5, Q5:Q21) %>%
# replace NAs with "none" for disability info
mutate(disability_nos = replace_na(disability_nos, "None"),
physical_chronic = replace_na(physical_chronic, "None"),
mental_health = replace_na(mental_health, "None"),
) %>% # recode gender data
mutate(gender_cleaned = case_when(Q6 %in% c("Female", "female", "Woman",
"woman",
"Cisgender woman",
"female (she/her)",
"F", "f", "Womxn",
"Woman (tranas)") ~ "Woman",
Q6 %in% c("Man", "man", "M", "m",
"Male (he/him)", "Male",
"male", "Trans man.") ~
"Man",
Q6 %in% c("Agender", "Genderfluid",
"GNC", "NB", "non-binary",
" Non-binary", "Non-Binary",
"Non-binary femme", "non-binary male",
"non binary", "Non binary",
"Nonbinary", "Queer", "Transmasculine",
"Non-binary") ~ "Non-binary",
TRUE ~ "Not stated")) %>%
# select necessary columns and tidy up the names
select(ResponseId,
"age" = Q5,
"gender" = Q6,
"mature" = Q7,
"level_study" = Q8,
"country" = Q9,
"subject" = Q10,
"english_first" = Q11,
"neurotype_open" = Q13,
"disability_open" = Q14,
"why_open" = Q18,
"how_open" = Q23,
"advantages" = Q20,
"disadvantages" = Q21,
everything()) In an earlier version of this book, providing this prompt resulting in it changing the code without telling me so that not only did it not do what I intended, it also didn’t work so you need to be very, very careful.
Using GPT-4 for this task resulted in incorrect comments, which then affected subsequent reasoning and introduced errors into the code.
If you use AI without thinking and accidentally commit research fraud, don’t blame me, I did try and warn you :)
To check that it hasn’t changed any code you can run all.equal() to compare two datasets. If it returns true, it means that the result of your initial code and the new code are identical. This is a really important check.
Here’s the code with the new comments:
# this is the code copied from Copilot with the edited comments
dat_copilot <- dat_raw %>%
filter(Progress > 94, # keep responses with >94% progress
DistributionChannel != "preview") %>% # exclude preview/test responses
select(ResponseId, "duration" = 5, Q5:Q21) %>% # select ID, rename column 5 as 'duration', keep Q5–Q21
# fill missing disability-related fields with "None"
mutate(disability_nos = replace_na(disability_nos, "None"),
physical_chronic = replace_na(physical_chronic, "None"),
mental_health = replace_na(mental_health, "None"),
) %>%
# standardise gender responses into four categories
mutate(gender_cleaned = case_when(Q6 %in% c("Female", "female", "Woman",
"woman",
"Cisgender woman",
"female (she/her)",
"F", "f", "Womxn",
"Woman (tranas)") ~ "Woman",
Q6 %in% c("Man", "man", "M", "m",
"Male (he/him)", "Male",
"male", "Trans man.") ~
"Man",
Q6 %in% c("Agender", "Genderfluid",
"GNC", "NB", "non-binary",
" Non-binary", "Non-Binary",
"Non-binary femme", "non-binary male",
"non binary", "Non binary",
"Nonbinary", "Queer", "Transmasculine",
"Non-binary") ~ "Non-binary",
TRUE ~ "Not stated")) %>%
# rename key columns for clarity and keep all remaining variables
select(ResponseId,
"age" = Q5,
"gender" = Q6,
"mature" = Q7,
"level_study" = Q8,
"country" = Q9,
"subject" = Q10,
"english_first" = Q11,
"neurotype_open" = Q13,
"disability_open" = Q14,
"why_open" = Q18,
"how_open" = Q23,
"advantages" = Q20,
"disadvantages" = Q21,
everything())
# then we can test if the two objects are identical to ensure it hasn't changed anything
all.equal(dat, dat_copilot)[1] TRUEall.equal() returns true which means the two datasets are identical.
5.4 Refactoring code
Refactoring means improving the structure of your code without changing what it does. You are not adding new features or fixing bugs, you are just making the code cleaner, easier to read, and easier to work with. Refactoring is like tidying your desk: everything still works the same, but it is more organised and makes future work easier.
Refactoring:
- Makes your code easier to read so that you (and others) can quickly understand what it does later on.
- Simplifies your code by breaking big, messy pieces into smaller, easier-to-manage parts.
- Keeps your code easy to update as clean, consistent code makes it easier to fix bugs or add new features later.
- Helps you avoid and remove duplicated or unnecessary code.
- Sometimes make it faster. Tidier code can help your program run more efficiently.
- Can help spot hidden problems. While cleaning up, you might notice bugs or logic errors that you had missed before.
Are you using GPT-5 as instructed? The next section goes very badly if you aren’t.
We’ll stick with the example of code from my publication because it’s complicated enough that there are likely improvements or alternative solutions. Enter the following prompt followed by the code (use the original, not the Copilot commented version):
I would like you to refactor the following code. Keep the behaviour and output exactly the same, but make the code cleaner, easier to read, and more efficient. Please:
Add helpful comments where needed. Use clear and consistent variable and function names. Remove any unnecessary repetition. Break long sections into smaller, logical parts if possible. Follow good coding style for R and use a tidyverse approach where possible. After refactoring, briefly explain what changes you made and why.
Here’s the refactored code it gave me:
# Clean and prepare the survey data
dat_copilot <- dat_raw %>%
# 1) Keep only near-complete, real responses
filter(
Progress > 94, # exclude incomplete responses
DistributionChannel != "preview" # exclude preview entries
) %>%
# 2) Retain core identifiers and items for analysis
# Note: 'duration = 5' selects the 5th column by position and renames it to 'duration'
select(
ResponseId,
duration = 5,
Q5:Q21
) %>%
# 3) Impute missing values for disability-related items with "None"
mutate(
across(
c(disability_nos, physical_chronic, mental_health),
~ tidyr::replace_na(.x, "None")
)
) %>%
# 4) Harmonise reported gender text into a clean categorical variable
mutate(
gender_cleaned = dplyr::case_when(
Q6 %in% c(
"Female", "female", "Woman", "woman", "Cisgender woman",
"female (she/her)", "F", "f", "Womxn", "Woman (tranas)"
) ~ "Woman",
Q6 %in% c(
"Man", "man", "M", "m", "Male (he/him)", "Male",
"male", "Trans man."
) ~ "Man",
Q6 %in% c(
"Agender", "Genderfluid", "GNC", "NB", "non-binary",
" Non-binary", "Non-Binary", "Non-binary femme",
"non-binary male", "non binary", "Non binary",
"Nonbinary", "Queer", "Transmasculine", "Non-binary"
) ~ "Non-binary",
TRUE ~ "Not stated"
)
) %>%
# 5) Final tidy selection and renaming for analytical clarity
select(
ResponseId,
age = Q5,
gender = Q6,
mature = Q7,
level_study = Q8,
country = Q9,
subject = Q10,
english_first = Q11,
neurotype_open = Q13,
disability_open= Q14,
why_open = Q18,
how_open = Q23,
advantages = Q20,
disadvantages = Q21,
dplyr::everything()
)And here’s the explanation:
What changed and why
- Structured the pipeline into five clearly labelled stages. Improves readability and helps future maintainers understand intent at a glance without scanning each line.
- Consistent tidyverse style and explicit namespaces where helpful. Retained %>%, used across() for grouped NA imputation, and added dplyr:: or tidyr:: qualifiers where ambiguity could arise in larger projects.
- Reduced repetition safely Replaced three separate mutate() calls for NA handling with a single mutate(across(…)), which is more concise and makes the imputation intent explicit while keeping the exact same behaviour.
- Clear, descriptive comments. Comments explain the purpose of each main step without annotating every line, matching your instruction and making the code easier to review.
- Preserved semantics of position-based selection for duration. Kept duration = 5 to ensure identical behaviour, as it renames the fifth column of the current data to duration.
Again, it’s very important to check that this refactored code has the same result as the original. There is no shortcut for knowing and checking your data.
5.5 Be critical
From both cognitive science and motivational psychology, writing your own comments and understanding your code before refactoring are key to developing genuine expertise and confidence. As we’ve mentioned several times already, research on retrieval practice shows that learning is stronger when you produce information yourself rather than copying or reading it. Writing your own code comments works like taking your own lecture notes: the act of explaining what your code does, in your own words, strengthens understanding and recall. Similarly, elaboration - adding meaning and connections - helps transform isolated code into a coherent mental model of whatever it is you’re doing
These processes also feed into psychological needs identified in self-determination theory: competence, autonomy, and relatedness. Each time you explain your code or verify that a refactor still works, you experience a small mastery moment, evidence that you can and do actually understand and control what you are doing. These mastery experiences are the foundation of self-efficacy, the belief that you can succeed in similar tasks in the future. Over time, writing and refining your own comments builds both technical skill and the confidence to tackle new coding challenges independently.
By contrast, outsourcing explanations or edits to AI may help short-term efficiency but undermines these motivational and cognitive benefits. When an AI provides ready-made comments or “cleaner” code, it might fuel the Dunning-Kruger effect, the systematic tendancy of people with low ability to over-estimate their competence. This false fluency weakens both comprehension and autonomy: the more you depend on external solutions, the less opportunity you have to consolidate your own knowledge and sense of competence.
In practice: write your own comments first, then use AI to critique or refine them. When refactoring, ensure you can explain what each variable represents, why each step exists, and how the data should behave before you let AI suggest changes. Doing so keeps you in control, supports your autonomy as a learner, and transforms code review from a mechanical task into an act of understanding.
I hadn’t used AI to perform these types of tasks before writing this book so here’s my takeaways:
- DID I MENTION? CHECK EVERYTHING.
- If you give an AI code, you simply cannot trust that it won’t change your code, even if that’s not the task you ask it to do. If you use AI to add or review comments, you must check the output. Tools like
all.equal()can help perform these checks. - You also can’t trust that the comments will be accurate. Anything an AI writes must be checked before you use it. If you don’t know if it’s right, don’t use it.
- Because you have to check what it does so carefully, don’t give it a big dump of code. Smaller chunks will end up taking less time.