| country_name | country_code | year | members | women |
|---|---|---|---|---|
| Argentina | ARG | 1950 | 34 | 0 |
| Argentina | ARG | 1975 | 69 | 3 |
| Argentina | ARG | 2000 | 72 | 2 |
| Argentina | ARG | 2025 | 72 | 33 |
| Brazil | BRA | 1950 | 63 | 0 |
| Brazil | BRA | 1975 | 66 | 0 |
| Brazil | BRA | 2000 | 81 | 6 |
| Brazil | BRA | 2025 | 81 | 16 |
8 Data Tidying
Intended Learning Outcomes
8.1 Functions used
- built-in (you can always use these without loading any packages)
- base::
library(),c(),list(),seq()
- base::
- tidyverse (you can use all these with
library(tidyverse))- readr::
read_csv() - dplyr::
summarise(),mutate(),filter(),select(),rename(),relocate() - tidyr::
pivot_longer(),pivot_wider(),separate() - ggplot2::
ggplot(),aes(), … - stringr::
str_to_title(),str_replace()
- readr::
- Other
- readxl::
read_xlsx() - janitor::
clean_names()
- readxl::
8.2 Set-up
Tip
- Open your
ADS-2026project - Download the Data tidying cheat sheet
- Download two data files into the “data” folder:
- Create a new quarto file called
08-tidy.qmd - Update the YAML header
- Replace the setup chunk with the one below
8.3 Data Structures
The data you work with will likely come in many different formats and structures. Some of these structures may be driven by how the software you use outputs the data, but data structures may also differ because of human intervention or attempts at organisation, some of which may not be particularly helpful.
Data cleaning and tidying will likely be the most time consuming and difficult task you perform. Whilst you can create code recipes for analyses and visualisations, as Hadley Whickham puts it, “every messy dataset is messy in its own way”, which means that you will often have to solve new problems that are specific to the dataset. Additionally, moving between data structures that are intuitive to read by humans and those that are useful for a computer requires a conceptual shift that only comes with practice.
This is all a verbose way of saying that what lies ahead in this chapter is unlikely to sink in on the first attempt and you will need to practice with different examples (preferably with data you know well) before you truly feel comfortable with it.
First, some terminology.
An observation is all the information about a single “thing” in a single condition, such as at one point in time. These things can be customers, sales, orders, feedback questionnaires, tweets, or really anything. Observations should have a way to identify them, such as a unique ID or a unique combination of values like country and year.
A variable is one type of information about the observation. For example, if the observation is a sale, the variables you might have about the sale are the sale ID, the customer’s ID, the date of the sale, the price paid, and method of payment.
A value is the data for one variable for one observation. For example, the value of the date variable from the observation of a sale might be 2021-08-20.
Tip
The following table is data that shows the percentage of women in parliament for each country and year.
- How many variables are there in this dataset?
- How many observations are there in this dataset?
- How many values are there in this dataset?
- What is
year? - What is
2025?
- There are 2 variables,
country_name,country_code, year,members, andwomen`. - There are 8 observations, one for each of 2 countries for each of 4 years.
- There are 40 values, one for each combination of the 8 observations (rows) and 5 variables (columns)
yearis a column name, also known as a variable2025is a value because it is a single data point for one variable for one observation.
8.3.1 Untidy data
First, let’s have a look at an example of a messy, or untidy, dataset about the proportion of women in the upper house of parliaments for several countries (data sourced from IPU Parline).
| country | 1950 | 1975 | 2000 | 2025 |
|---|---|---|---|---|
| Argentina (ARG) | 0 / 34 | 3 / 69 | 2 / 72 | 33 / 72 |
| Brazil (BRA) | 0 / 63 | 0 / 66 | 6 / 81 | 16 / 81 |
| Chile (CHL) | 0 / 45 | 2 / 50 | 2 / 49 | 13 / 50 |
| Italy (ITA) | 4 / 342 | 6 / 322 | 26 / 326 | 74 / 204 |
| Jordan (JOR) | 0 / 20 | 0 / 30 | 3 / 40 | 10 / 69 |
| Philippines (PHL) | 0 / 8 | 1 / 8 | 4 / 23 | 5 / 24 |
| United States of America (USA) | 1 / 100 | 0 / 100 | 13 / 100 | 26 / 100 |
- Each row has all of the data relating to one country.
- The
countrycolumn contains two values (name and code) - The
{year}columns contain the number of women / members. - There is data for four different years in the dataset.
Let’s say you wanted to calculate the average proportion of women in parliaments each year. You can’t perform mathematical operations on the {year} columns because they are character data types.
You would probably normally use Excel to
- split
1950column intowomen_1950andmembers_1950columns - split
1975column intowomen_1975andmembers_1975columns - split
2000column intowomen_2000andmembers_2000columns - split
2025column intowomen_2025andmembers_2025columns - calculate
women_1950/members_1950as a new columnprop_1950 - calculate
women_1975/members_1975as a new columnprop_1975 - calculate
women_2000/members_2000as a new columnprop_2000 - calculate
women_2025/members_2025as a new columnprop_2025 - calculate the average of the columns
prop_1950,prop_1975,prop_2000, andprop_2025
Tip
Think about how many steps in Excel this would be if there were 10 years in the table, or a different number of years each time you encountered data like this.
8.3.2 Tidy data
There are three rules for “tidy data, which is data in a format that makes it easier to combine data from different tables, create summary tables, and visualise your data.
- Each observation must have its own row
- Each variable must have its own column
- Each value must have its own cell
This is the tidy version:
| country_name | country_code | year | members | women |
|---|---|---|---|---|
| Argentina | ARG | 1950 | 34 | 0 |
| Argentina | ARG | 1975 | 69 | 3 |
| Argentina | ARG | 2000 | 72 | 2 |
| Argentina | ARG | 2025 | 72 | 33 |
| Brazil | BRA | 1950 | 63 | 0 |
| Brazil | BRA | 1975 | 66 | 0 |
| Brazil | BRA | 2000 | 81 | 6 |
| Brazil | BRA | 2025 | 81 | 16 |
| Chile | CHL | 1950 | 45 | 0 |
| Chile | CHL | 1975 | 50 | 2 |
| Chile | CHL | 2000 | 49 | 2 |
| Chile | CHL | 2025 | 50 | 13 |
| Italy | ITA | 1950 | 342 | 4 |
| Italy | ITA | 1975 | 322 | 6 |
| Italy | ITA | 2000 | 326 | 26 |
| Italy | ITA | 2025 | 204 | 74 |
| Jordan | JOR | 1950 | 20 | 0 |
| Jordan | JOR | 1975 | 30 | 0 |
| Jordan | JOR | 2000 | 40 | 3 |
| Jordan | JOR | 2025 | 69 | 10 |
| Philippines | PHL | 1950 | 8 | 0 |
| Philippines | PHL | 1975 | 8 | 1 |
| Philippines | PHL | 2000 | 23 | 4 |
| Philippines | PHL | 2025 | 24 | 5 |
| United States of America | USA | 1950 | 100 | 1 |
| United States of America | USA | 1975 | 100 | 0 |
| United States of America | USA | 2000 | 100 | 13 |
| United States of America | USA | 2025 | 100 | 26 |
- Each row is a country’s data for a particular year.
- There are now five variables (columns) because there are five different types of information we have for each observation: the country name, its 3-letter code, the year, number of members of parliament, and the number of women in parliament.
- The number of
membersandwomenare in separate columns, so now you can perform mathematical operations on them.
To calculate the average proportion of women in parliaments each year in R, you could then:
- calculate the proportion of women for each country and year by dividing
womenbymembers - calculate the average of this value for each year
| year | avg_prop_women |
|---|---|
| 1950 | 0.0030994 |
| 1975 | 0.0324445 |
| 2000 | 0.0859051 |
| 2025 | 0.2702672 |
Note
If there were 10 years in the table, or a different number of years each time you encountered data like this, the code for producing the tables and plots above never changes.
If you have control over how the data are recorded, it will make your life easier to record it in a tidy format from the start. However, we don’t always have control, so this class will also teach you how to convert untidy tables into tidy tables.
8.4 Reshaping Data
Data tables can be in wide format or long format (or a mix of the two). Wide data are where all of the observations about one thing are in the same row, while long data are where each observation is on a separate row. You often need to convert between these formats to do different types of summaries or visualisation. You may have done something similar using pivot tables in Excel.
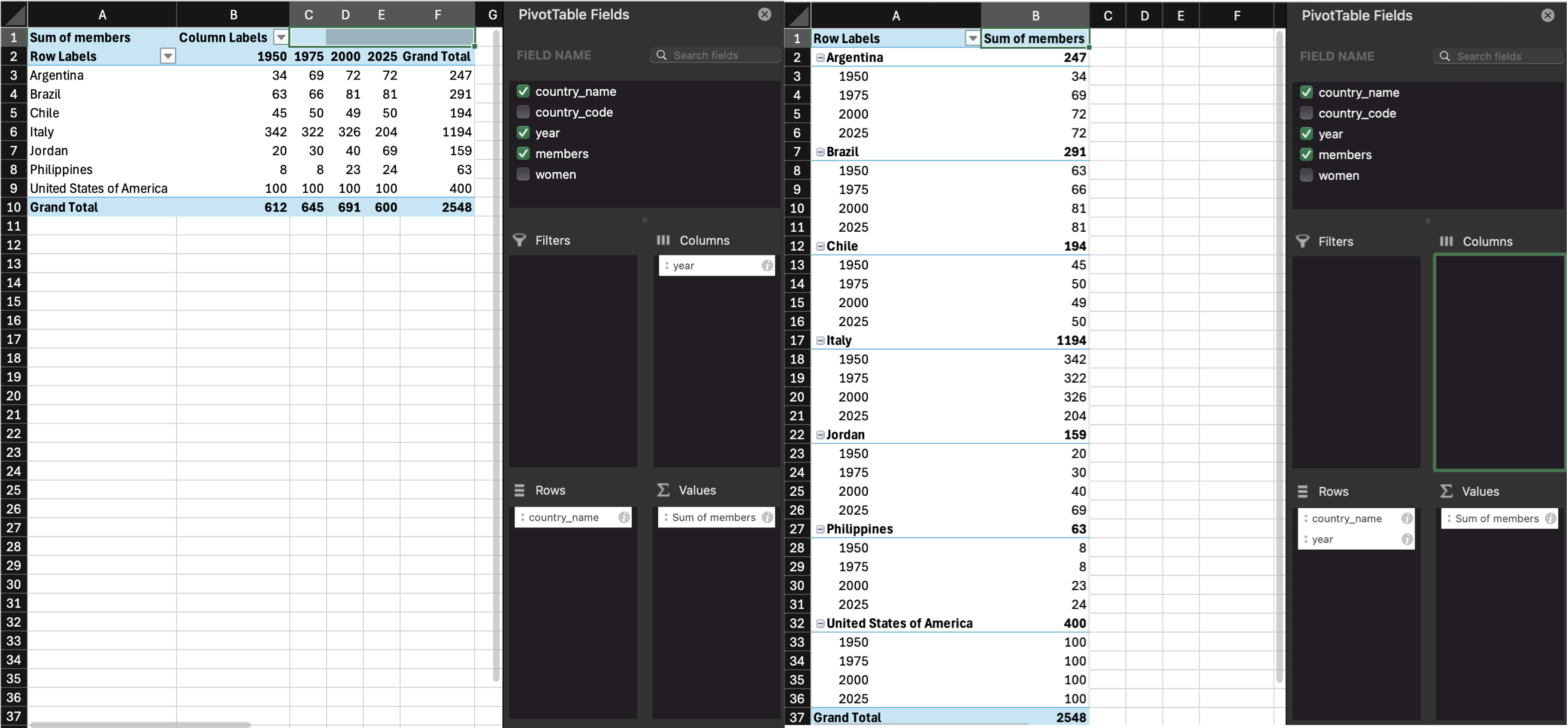
Our untidy table is in wide format, where each row is a country, and represents the data from several years. This is a really intuitive way for humans to read a table, but it’s not as easy to process with code.
8.4.1 Wide to long
The function pivot_longer() converts a wide data table to a longer format by converting the headers from specified columns into the values of new columns, and combining the values of those columns into a new condensed column.
This function has several arguments:
cols: the columns you want to make long; you can refer to them by their names, likec(`1950`, `1975`, `2020`, `2025)or`1950`:`2025`or by their numbers, likec(2, 3, 4, 5)or2:5names_to: what you want to call the new columns that thecolscolumn header names will go intovalues_to: what you want to call the new column that contains the values in thecols
With the pivot functions, it can be easier to show than tell - run the below code and then compare untidy with long and the pivot code and try to map each argument to what has changed.
| country | year | women_members |
|---|---|---|
| Argentina (ARG) | 1950 | 0 / 34 |
| Argentina (ARG) | 1975 | 3 / 69 |
| Argentina (ARG) | 2000 | 2 / 72 |
| Argentina (ARG) | 2025 | 33 / 72 |
| Brazil (BRA) | 1950 | 0 / 63 |
| Brazil (BRA) | 1975 | 0 / 66 |
| Brazil (BRA) | 2000 | 6 / 81 |
| Brazil (BRA) | 2025 | 16 / 81 |
| Chile (CHL) | 1950 | 0 / 45 |
| Chile (CHL) | 1975 | 2 / 50 |
| Chile (CHL) | 2000 | 2 / 49 |
| Chile (CHL) | 2025 | 13 / 50 |
| Italy (ITA) | 1950 | 4 / 342 |
| Italy (ITA) | 1975 | 6 / 322 |
| Italy (ITA) | 2000 | 26 / 326 |
| Italy (ITA) | 2025 | 74 / 204 |
| Jordan (JOR) | 1950 | 0 / 20 |
| Jordan (JOR) | 1975 | 0 / 30 |
| Jordan (JOR) | 2000 | 3 / 40 |
| Jordan (JOR) | 2025 | 10 / 69 |
| Philippines (PHL) | 1950 | 0 / 8 |
| Philippines (PHL) | 1975 | 1 / 8 |
| Philippines (PHL) | 2000 | 4 / 23 |
| Philippines (PHL) | 2025 | 5 / 24 |
| United States of America (USA) | 1950 | 1 / 100 |
| United States of America (USA) | 1975 | 0 / 100 |
| United States of America (USA) | 2000 | 13 / 100 |
| United States of America (USA) | 2025 | 26 / 100 |
Warning
Note that because the names of the columns are numbers, they need to be wrapped in backticks otherwise pivot_longer will think you mean the 1950th column through the 2025th column and you’ll get an error like:
Error in `pivot_longer()`:
! Can't select columns past the end.
ℹ Locations 1950, 1951, 1952, …, 2024, and 2025 don't exist.
ℹ There are only 5 columns.
Tip
Create a long version of the following table of how many million followers each band has on different social media platforms. You don’t need to use code, just sketch it in a notebook or make a table in a spreadsheet.
| band | ||
|---|---|---|
| The Beatles | 3.8 | 3.8 |
| The Rolling Stones | 3.4 | 3.1 |
| One Direction | 31.3 | 22.8 |
Your answer doesn’t need to have the same column headers or be in the same order.
| account | social_media | followers |
|---|---|---|
| The Beatles | 3.8 | |
| The Beatles | 3.8 | |
| The Rolling Stones | 3.4 | |
| The Rolling Stones | 3.1 | |
| One Direction | 31.3 | |
| One Direction | 322.8 |
Note
If you’re a researcher and you’re used to thinking about IVs and DVs, you may find it easier to remember that each IV and DV should have its own column, rather than a column for each level of the IV.
8.4.2 Long to wide
We can also go from long to wide format using the pivot_wider() function. Instead of returning to the original table with a row for each customer and a column for each year, this new wide table will have a row for each year and a column for each country.
id_cols: the column(s) that uniquely identify each new rownames_from: the column(s) that contain your new column headersvalues_from: the column that contains the values for the new columns
| year | Argentina (ARG) | Brazil (BRA) | Chile (CHL) | Italy (ITA) | Jordan (JOR) | Philippines (PHL) | United States of America (USA) |
|---|---|---|---|---|---|---|---|
| 1950 | 0 / 34 | 0 / 63 | 0 / 45 | 4 / 342 | 0 / 20 | 0 / 8 | 1 / 100 |
| 1975 | 3 / 69 | 0 / 66 | 2 / 50 | 6 / 322 | 0 / 30 | 1 / 8 | 0 / 100 |
| 2000 | 2 / 72 | 6 / 81 | 2 / 49 | 26 / 326 | 3 / 40 | 4 / 23 | 13 / 100 |
| 2025 | 33 / 72 | 16 / 81 | 13 / 50 | 74 / 204 | 10 / 69 | 5 / 24 | 26 / 100 |
8.5 One value per cell
The cells in the women_members column actually contain two different values. We need to split it into two columns for the variables women, and members.
You can split a column into parts with the function tidyr::separate(). There is a ” / ” between the two values, so we can split it along this – if you are in charge of how data is stored, ensuring data is entered consistently makes this much easier.
tidyr::separate()
| country | year | women | members |
|---|---|---|---|
| Argentina (ARG) | 1950 | 0 | 34 |
| Argentina (ARG) | 1975 | 3 | 69 |
| Argentina (ARG) | 2000 | 2 | 72 |
| Argentina (ARG) | 2025 | 33 | 72 |
| Brazil (BRA) | 1950 | 0 | 63 |
| Brazil (BRA) | 1975 | 0 | 66 |
| Brazil (BRA) | 2000 | 6 | 81 |
| Brazil (BRA) | 2025 | 16 | 81 |
| Chile (CHL) | 1950 | 0 | 45 |
| Chile (CHL) | 1975 | 2 | 50 |
| Chile (CHL) | 2000 | 2 | 49 |
| Chile (CHL) | 2025 | 13 | 50 |
| Italy (ITA) | 1950 | 4 | 342 |
| Italy (ITA) | 1975 | 6 | 322 |
| Italy (ITA) | 2000 | 26 | 326 |
| Italy (ITA) | 2025 | 74 | 204 |
| Jordan (JOR) | 1950 | 0 | 20 |
| Jordan (JOR) | 1975 | 0 | 30 |
| Jordan (JOR) | 2000 | 3 | 40 |
| Jordan (JOR) | 2025 | 10 | 69 |
| Philippines (PHL) | 1950 | 0 | 8 |
| Philippines (PHL) | 1975 | 1 | 8 |
| Philippines (PHL) | 2000 | 4 | 23 |
| Philippines (PHL) | 2025 | 5 | 24 |
| United States of America (USA) | 1950 | 1 | 100 |
| United States of America (USA) | 1975 | 0 | 100 |
| United States of America (USA) | 2000 | 13 | 100 |
| United States of America (USA) | 2025 | 26 | 100 |
Tip
Figure out how to split the country column into country_name and country_code. There are a few ways to do it, but the example below takes advantage of the fact that the default sep argument will split at any characters that aren’t letters or numbers, so will split “Brazil (BRA)” into “Brazil”, “BRA”, and ““.
8.6 Pipes
We’ve already introduced pipes in Section 4.2 but this type of data processing is where they really start to shine, as they can significantly reduce the amount of code you write.
As a recap, a pipe takes the result of the previous function and sends it to the next function as its first argument, which means that you do not need to create intermediate objects. Below is all the code we’ve used in this chapter, and in the process we created four objects. This can get very confusing in longer scripts.
untidy <- read_csv("data/untidy.csv", show_col_types = FALSE)
long <- pivot_longer(
data = untidy,
cols = `1950`:`2025`,
names_to = "year",
values_to = "women_members"
)
split_data <- separate(
data = long,
col = women_members,
into = c("women", "members"),
sep = " / ",
remove = TRUE,
convert = TRUE
)
tidy_data <- separate(
data = split_data,
col = country,
into = c("country_name", "country_id"),
extra = "drop"
)
Warning
You can give each object the same name and keep replacing the old data object with the new one at each step. This will keep your environment clean, but it makes debugging code much harder.
For longer series of steps like the one above, using pipes can eliminate many intermediate objects. This also makes it easier to add an intermediate step to your process without having to think of a new table name and edit the table input to the next step (which is really easy to accidentally miss).
tidy_data <- read_csv(file = "data/untidy.csv", show_col_types = FALSE) |>
pivot_longer(
cols = `1950`:`2025`,
names_to = "year",
values_to = "women_members"
) |>
separate(
col = women_members,
into = c("women", "members"),
sep = " / ",
remove = TRUE,
convert = TRUE
) |>
separate(
col = country,
into = c("country_name", "country_id"),
extra = "drop"
)You can read the code above like this:
Read the data with
read_csv()file: from the file at r path(“data/untidy.csv”)`,show_col_types: do not show the column types message;- and then
Reshape the data longer with
pivot_longer()cols: take the columns from1950to2025,names_to: create a new column called “year” from thecolsheader names,values_to: create a new column called “women_members” from thecolsvalues,- and then
Split multiple values in the same column with
separate()col: separate the columnwomen_members,into: into new columns called “women” and “members”,sep: separate the values at each ” / “,remove: do remove the old column,convert: do convert the new columns into the right data types;- and then
Split multiple values in the same column with
separate()col: separate the columncountry,into: into new columns called “country_name” and “country_code”,extra: if there are extra values, drop them;
Don’t feel like you always need to get all of your data wrangling code into a single pipeline. You should make intermediate objects whenever you need to break up your code because it’s getting too complicated or if you need to debug something.
Note
You can debug a pipe by highlighting from the beginning to just before the pipe you want to stop at. Try this by highlighting from data <- to the end of the separate function and typing command-enter (mac) or control-enter (PC). What does data look like now?
8.7 Realistic Example
Let’s load a fairly messy dataset to do some realistic data processing.
8.7.1 Read in data
If you try to read it in before you look at it, you’ll see the column names are a mess because there are 16 rows of text before the main table. So let’s skip those 16 rows and use janitor::clean_names() to fix the names.
Have a look at the first 10 columns (we already know there are a ton of year columns).
Rows: 289
Columns: 10
$ index <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12…
$ variant <chr> "Estimates", "Estimates", "Estimates"…
$ region_subregion_country_or_area <chr> "WORLD", "UN development groups", "Mo…
$ notes <chr> NA, "a", "b", "c", "d", "e", NA, "f",…
$ country_code <dbl> 900, 1803, 901, 902, 941, 934, 948, 1…
$ type <chr> "World", "Label/Separator", "Developm…
$ parent_code <dbl> 0, 900, 1803, 1803, 902, 902, 1803, 1…
$ x1950 <chr> "2536431.0180000002", "...", "814818.…
$ x1951 <chr> "2584034.227", "...", "824003.5119999…
$ x1952 <chr> "2630861.69", "...", "833720.17299999…The population values for each year all imported as characters. We could fix that on import, but it’s actually easier to fix it later once the dataset is long and all those values are in a single column.
8.7.2 Fill data
You’ll also see a bunch of highlighted rows that are aggregate data. We only want to look at countries, so we want to filter the result to just the countries, but then we wouldn’t know what region they’re from. Here’s a trick if you have data that are organised like this.
pop <- readxl::read_xlsx(file, skip = 16) |>
janitor::clean_names() |>
1 rename(country = 3) |>
2 mutate(region = ifelse(type == "SDG region", country, NA),
subregion = ifelse(type == "Subregion", country, NA)) |>
3 fill(region, subregion) |>
4 relocate(region, subregion, .after = country) |>
5 filter(type == "Country/Area")- 1
- Fix the long name in column 3
- 2
- Make two new columns, region and subregion, and give them the same value as the country column if the Type column is “SDG region” or “Subregion, and NA otherwise
- 3
-
fill()fills in the NAs in a column with nearest value above it - 4
- Move the new columns where they’ll make more sense
- 5
- Filter the dataset to only country rows
fill() to add region and subregion
| index | variant | country | region | subregion |
|---|---|---|---|---|
| 27 | Estimates | Burundi | SUB-SAHARAN AFRICA | Eastern Africa |
| 28 | Estimates | Comoros | SUB-SAHARAN AFRICA | Eastern Africa |
| 29 | Estimates | Djibouti | SUB-SAHARAN AFRICA | Eastern Africa |
| 30 | Estimates | Eritrea | SUB-SAHARAN AFRICA | Eastern Africa |
| 31 | Estimates | Ethiopia | SUB-SAHARAN AFRICA | Eastern Africa |
8.7.3 Wide to long
Now we have data from 1950 to 2020 each in their own column, so we need to make this table longer.
pop <- readxl::read_xlsx(file, skip = 16) |>
janitor::clean_names() |>
rename(country = 3) |>
mutate(region = ifelse(type == "SDG region", country, NA),
subregion = ifelse(type == "Subregion", country, NA)) |>
fill(region, subregion) |>
relocate(region, subregion, .after = country) |>
filter(type == "Country/Area") |>
pivot_longer(x1950:x2020,
names_to = "year",
values_to = "population"
)| index | variant | country | region | subregion | notes | country_code | type | parent_code | year | population |
|---|---|---|---|---|---|---|---|---|---|---|
| 193 | Estimates | Ecuador | LATIN AMERICA AND THE CARIBBEAN | South America | NA | 218 | Country/Area | 931 | x1977 | 7383.7129999999997 |
| 228 | Estimates | Tuvalu | OCEANIA (EXCLUDING AUSTRALIA AND NEW ZEALAND) | Polynesia | NA | 798 | Country/Area | 957 | x1983 | 8.0410000000000004 |
| 129 | Estimates | China, Hong Kong SAR | EASTERN AND SOUTH-EASTERN ASIA | Eastern Asia | 10 | 344 | Country/Area | 906 | x1992 | 5864.7449999999999 |
| 281 | Estimates | Monaco | EUROPE AND NORTHERN AMERICA | Western Europe | NA | 492 | Country/Area | 926 | x1967 | 23.292000000000002 |
| 270 | Estimates | San Marino | EUROPE AND NORTHERN AMERICA | Southern Europe | NA | 674 | Country/Area | 925 | x1969 | 18.98 |
| 155 | Estimates | Bonaire, Sint Eustatius and Saba | LATIN AMERICA AND THE CARIBBEAN | Caribbean | 15 | 535 | Country/Area | 915 | x1980 | 11.209 |
| 111 | Estimates | Kazakhstan | CENTRAL AND SOUTHERN ASIA | Central Asia | NA | 398 | Country/Area | 5500 | x2013 | 17026.117999999999 |
| 272 | Estimates | Slovenia | EUROPE AND NORTHERN AMERICA | Southern Europe | NA | 705 | Country/Area | 925 | x1993 | 2000.56 |
| 189 | Estimates | Bolivia (Plurinational State of) | LATIN AMERICA AND THE CARIBBEAN | South America | NA | 68 | Country/Area | 931 | x1961 | 3728.9540000000002 |
| 174 | Estimates | Sint Maarten (Dutch part) | LATIN AMERICA AND THE CARIBBEAN | Caribbean | 15 | 534 | Country/Area | 915 | x1965 | 4.46 |
8.7.4 Clean up
Now we can clean up some things.
pop <- readxl::read_xlsx(file, skip = 16) |>
janitor::clean_names() |>
rename(country = 3) |>
mutate(region = ifelse(type == "SDG region", country, NA),
subregion = ifelse(type == "Subregion", country, NA)) |>
fill(region, subregion) |>
relocate(region, subregion, .after = country) |>
filter(type == "Country/Area") |>
pivot_longer(x1950:x2020,
names_to = "year",
1 names_prefix = "x",
2 names_transform = list(year = as.integer),
values_to = "population",
3 values_transform = list(population = as.numeric),
) |>
4 select(country, region, subregion, year, population) |>
5 mutate(population = round(population, 3)) |>
6 mutate(region = str_to_title(region),
7 region = str_replace(region, "And", "&"))- 1
- Remove the “x” prefix from the column names to pivot
- 2
-
When you use pivot_longer, column names always become character data type, even if they are strings like “2020”, so you can use
names_transformto transform the names into a different data type. - 3
- Since the excel file was structured so oddly, all of the population data read in as characters. Now that we have gotten rid of values in that column that aren’t numbers, we can convert it to a numeric column.
- 4
- Narrow down to just the columns we want.
- 5
- Excel sometimes produces rounding artifacts, so round to 3 digits.
- 6
- Make the region in title case instead of all caps.
- 7
- Making region title case created a bunch of “And”, which we replace with “&”.
| country | region | subregion | year | population |
|---|---|---|---|---|
| Bosnia and Herzegovina | Europe & Northern America | Southern Europe | 1957 | 3049.928 |
| China, Macao SAR | Eastern & South-Eastern Asia | Eastern Asia | 1987 | 308.181 |
| Guatemala | Latin America & The Caribbean | Central America | 1952 | 3311.525 |
| Marshall Islands | Oceania (Excluding Australia & New Zealand) | Micronesia | 1982 | 33.330 |
| Myanmar | Eastern & South-Eastern Asia | South-Eastern Asia | 1985 | 37977.087 |
| New Caledonia | Oceania (Excluding Australia & New Zealand) | Melanesia | 2002 | 225.482 |
| Hungary | Europe & Northern America | Eastern Europe | 1996 | 10332.451 |
| Palau | Oceania (Excluding Australia & New Zealand) | Micronesia | 2020 | 18.092 |
| Grenada | Latin America & The Caribbean | Caribbean | 1993 | 98.234 |
| Madagascar | Sub-Saharan Africa | Eastern Africa | 1980 | 8716.549 |
8.7.5 Plot the data
Now that we’ve put all this work into making a useful, tidy dataset, let’s do something with it! First, calculate the total population in each region for each year.
Now plot it.
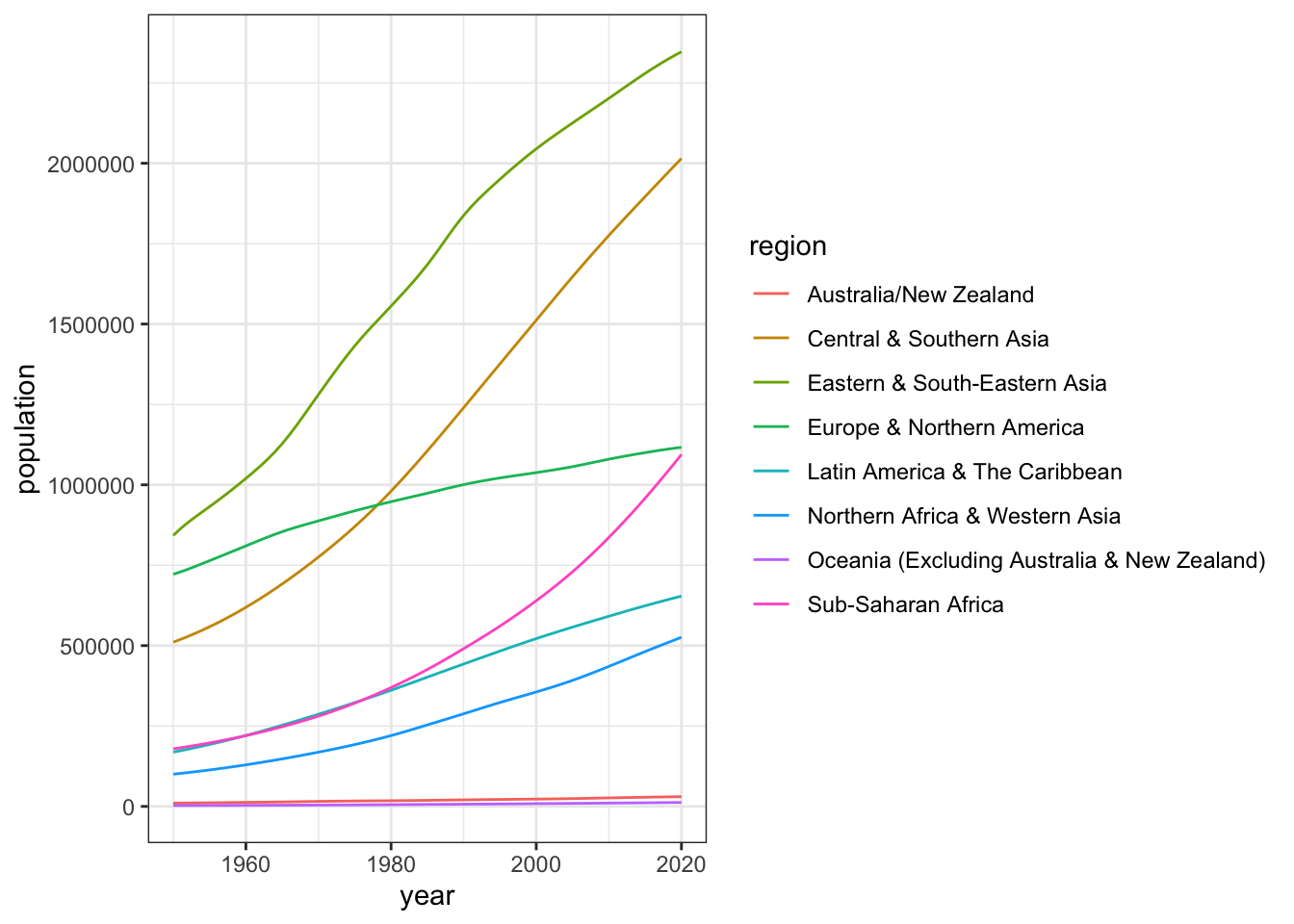
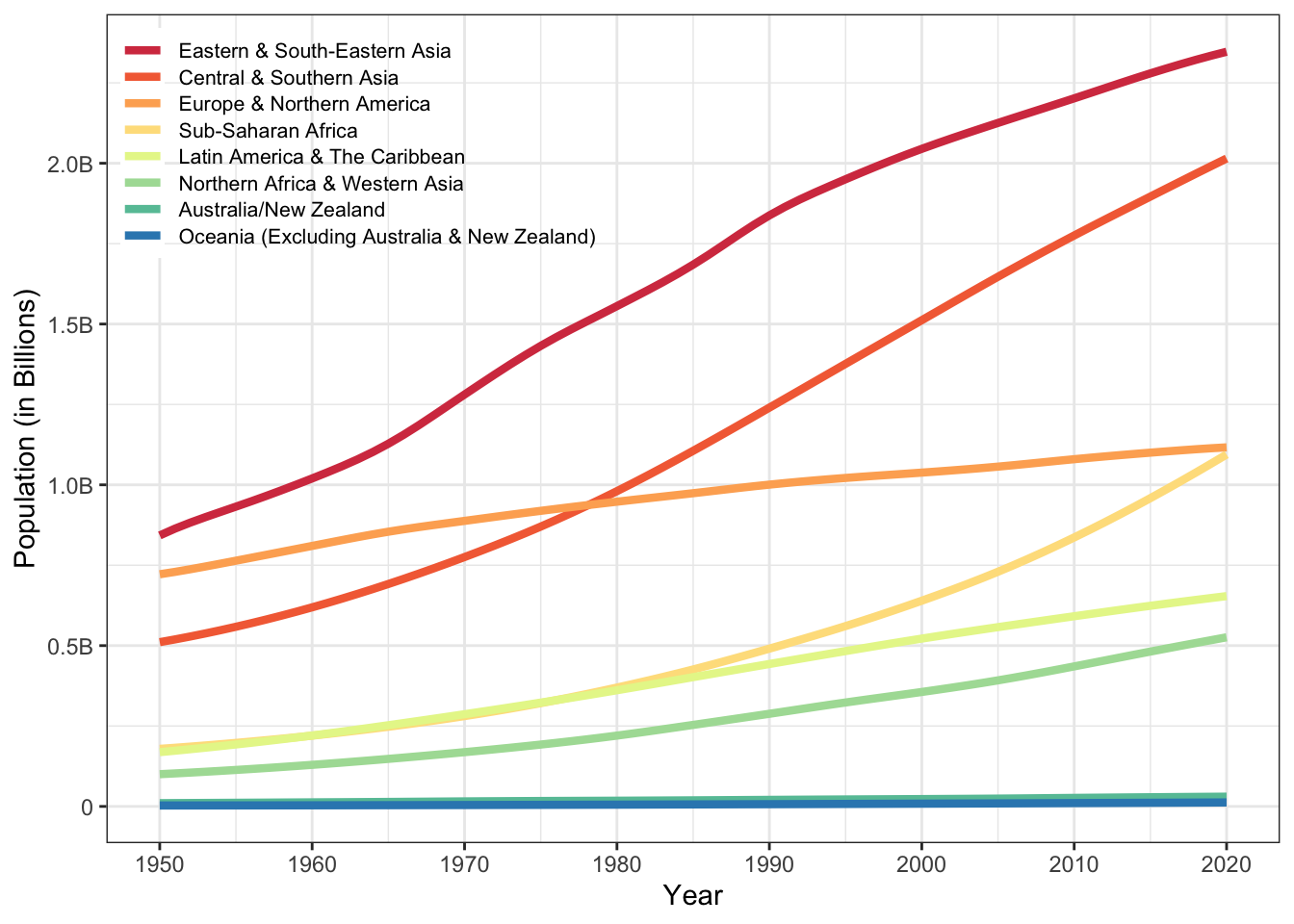
It’s OK, but we could do better. Here’s a trick to get the regions into the same order as they are at the right side of the plot. There is also some code to move the legend on top of the plot and other visual improvements.
region_order <- by_region |>
filter( year == 2020) |>
arrange(desc(population)) |>
pull(region)
# set region as a factor in desc 2020 population order
by_region$region <- factor(by_region$region, region_order)
ggplot(by_region, aes(x = year, y = population, colour = region)) +
geom_line(linewidth = 1.5) +
scale_x_continuous(breaks = seq(1950, 2020, 10)) +
scale_y_continuous(breaks = seq(0, 2.5e6, 5e5),
labels = c(0, "0.5B", "1.0B", "1.5B", "2.0B", "2.5B")) +
scale_colour_brewer(palette = "Spectral") +
labs(x = "Year", y = "Population (in Billions)", colour = NULL) +
guides(colour = guide_legend(position = "inside")) +
theme(legend.position = c(0, 1), legend.background = element_blank(),
legend.justification = c(0, 1),
legend.key.spacing.y = unit(-7, "pt"),
legend.text = element_text(size = 8)
)
8.8 Peer Coding Exercises
If you are enrolled on PSYCH1012 Applied Data Skills, do not do these exercises until the Tuesday workshop.
Tip
It’s very unlikely that you will get through all of the exercises during the class time - just do as many as you can as a pair. However, given that reshaping data is one of the biggest conceptual leaps in ADS, it will be worth finishing them at home on your own (or you could continue as a pair after class, that would be great).
Decide who is going to start as the Driver and Navigator. Remember to switch every so often. The Navigator will find it helpful to have a copy of these instructions open and read the next step to the Driver.
Open RStudio, ensure the environment is clear, and restart R.
Create a new quarto document and save it as
ads-week8-pivot.qmdDownload a copy of wide_exercise-1.csv{download} and wide_exercise-2.csv{download} into your data folder.
In the set-up code chunk, load the
tidyverse then load the two data files in usingread_csv()and name the objectswide1andwide2.
The two datasets represent simulated data from a patient satisfaction survey. We’ll do them one at a time, as they differ in complexity.
8.8.1 Survey 1
wide1 has data from 50 patients who were asked five questions about their most recent experience at a health centre. The results from this questionnaire are typically reported as a single overall satisfaction score, which is calculated by taking the mean of the five responses. Additionally, the survey also records whether the patient was attending the clinic for the first time, or as a repeat patient.
- Use your method of choice to look at the dataset and familiarise yourself with its structure and data. The Navigator should describe, in words, what “tidy” should look like before you write any code.
As noted, it’s important to think through what your tidied data should look like. Often, the problem with data wrangling in R isn’t actually the code, it’s a lack of understanding of the data that’s being worked on.
- How many variables should the long-form version of
widehave? - How many observations should the long-form version of
wide1have?
- There should be four variables, as there are 4 types of data: patient id, whether they are a repeat patient, the question they were asked, and their response.
- There will be 250 observations or rows of data because each patient will have 5 rows of data (one per question) and there are 50 patients (50 * 5 = 250).
- Transform
wide1to long-form usingpivot_longer()and store it in an object namedtidy1
- Confirm you have 250 rows and that is one row per patient per question.
8.8.2 Survey 2
wide2 also has data from 50 patients, however, there are now two measures included in the questionnaire. There are still five questions that relate to satisfaction, but there are also five questions that relate to whether the patient would recommend the medical practice to a friend. Both measures are typically reported by calculating an overall mean for each of the five items.
- Use your method of choice to look at the dataset and familiarise yourself with its structure and data. The Navigator should describe, in words, what “tidy” should look like before you write any code.
This is not as simple as the first exercise because there’s two potential ways you might tidy this data, depending on what you want to do with it and how you conceptualise the different measurements. It’s important to recognise that many of your coding problems will not have just one solution or approach which is why transparency is so vital.
8.8.2.1 Tidy 2a
For the first option, we’re going to treat the “satisfaction” and “recommendation” measurements as two categories of the same variable. This will be a fully long-form data set with five variables id, repeat_patient, question (the question number), category (whether it’s sat or rec), and response (the numerical rating).
- How many observations should the fully long-form version of
wide2have?
There will be 500 rows of data because each participant will have 10 rows: 5 for the satisfaction questions and five for the recommendation questions.
- Transform
wide2to full long-form usingpivot_longer()and store it in an object namedtidy2a. This exercise requires multiple steps and you may need to look at the help documentation.
8.8.2.2 Tidy 2b
The second option is to treat the satisfaction and recommendation scores as two distinct variables. This only makes sense if the satisfaction and recommendation scores for each question number are related to each other (e.g., q1 is about the same thing for both questions), making them part of the same observation.
This version should also have five variables, but it won’t be fully tidy, it’ll be a slight mix of the two that we’re going to call “semi-tidy”. The variables in the semi-tidy version will be id, repeat, question (the question number), sat (the response for the satisfaction question), and rec (the response for the recommendation question).
- How many observations should the semi-tidy version of
wide2have?
There will be 250 rows of data because, just like tidy1, each participant will have 5 rows, one for each of the five questions. The different responses to the satisfaction and recommendation questions are in different variables.
- Transform
wide2to semi-tidy usingpivot_longer()and store it in an object namedtidy2b. This exercise requires multiple steps and you may need to look at the help documentation.
You can reuse the code from tidy2a, you just need to add on an extra line that makes the data slightly wider.
Using
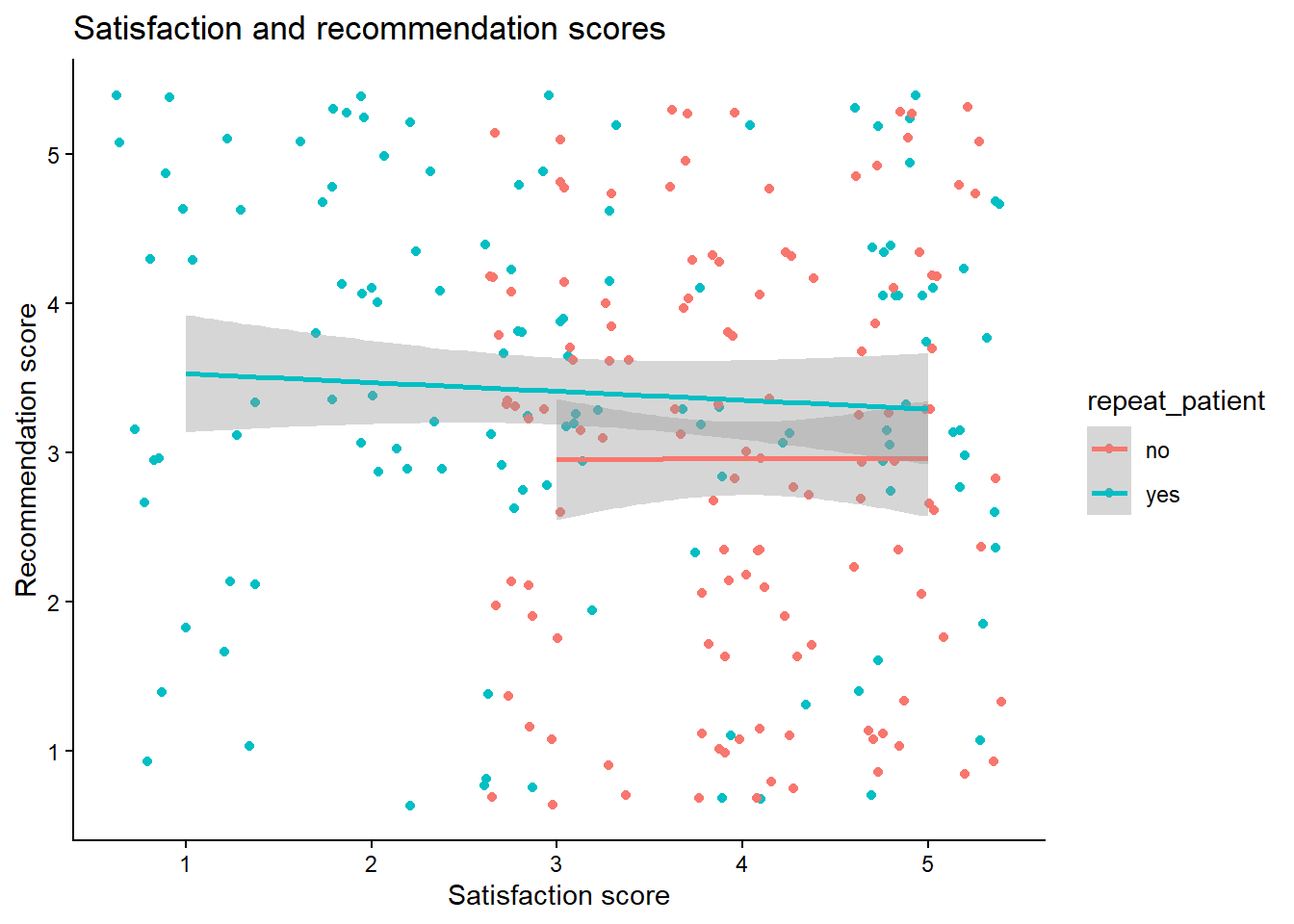
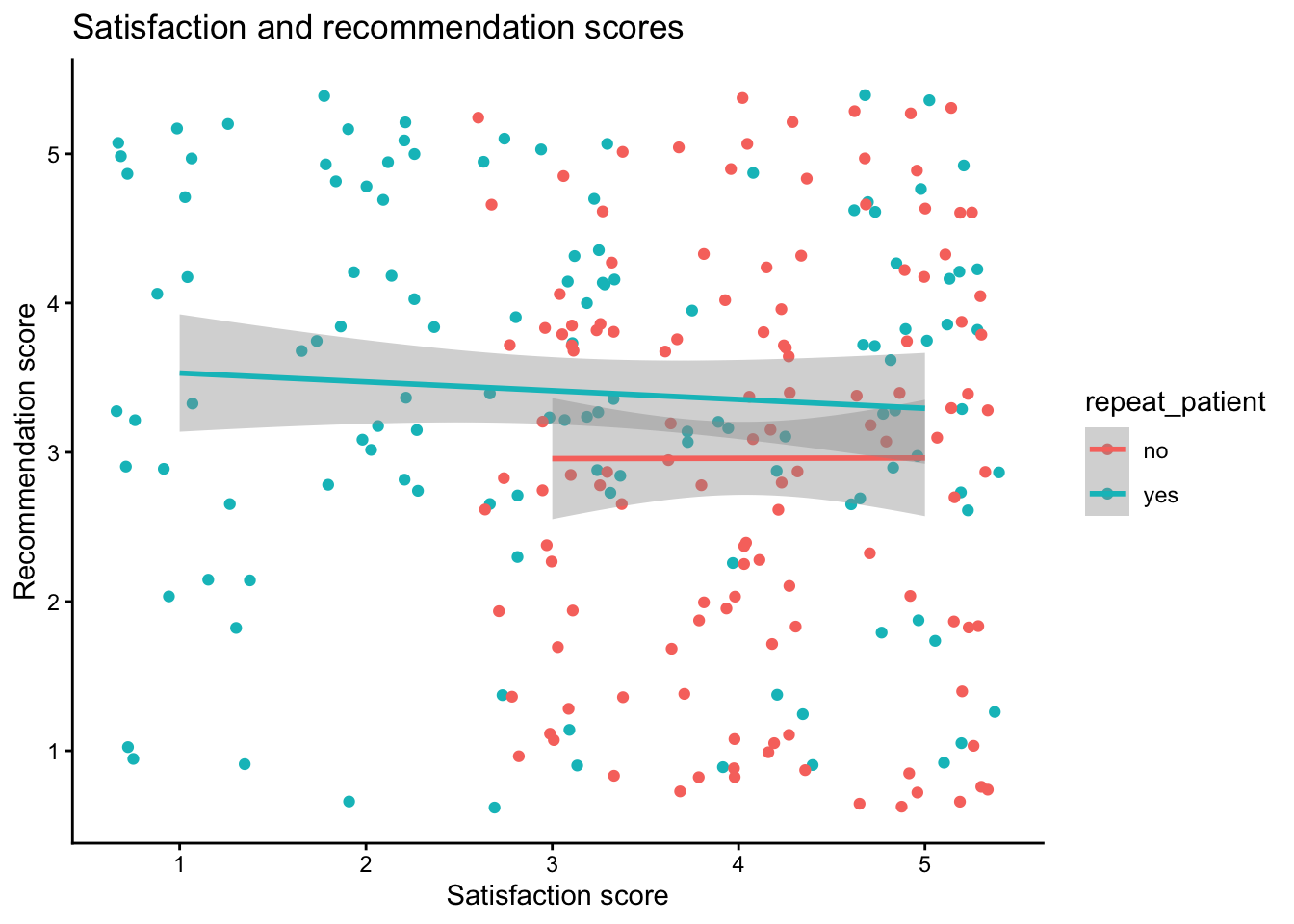
summarise(), calculate the mean score for each participant for both satisfaction and recommendation. Do this for both versions of the dataset so that you can see how the structure of the dataset changes the approach you need to take.Replicate the following scatterplot showing the relationship between satisfaction and recommendation scores, by whether the patient is a repeat patient.
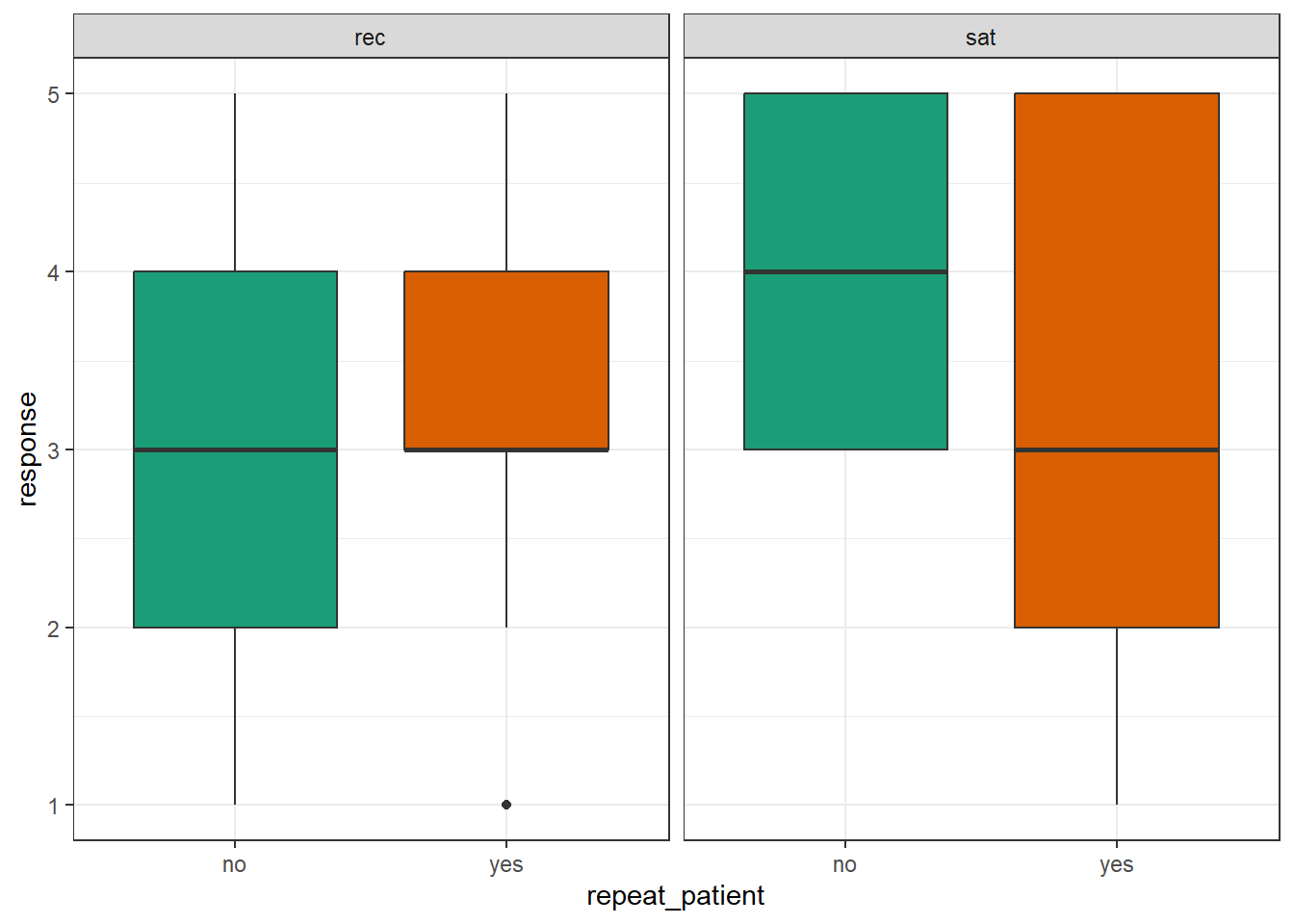
- Replicate the following boxplots showing satisfaction and recommends scores for new and repeat patients separately.
- Replicate the following histogram showing the distribution of all responses, across questions and categories.
8.9 Glossary
| term | definition |
|---|---|
| character | A data type representing strings of text. |
| data-type | The kind of data represented by an object. |
| long | A data format where each observation is on a separate row |
| observation | All of the data about a single trial or question. |
| tidy-data | A format for data that maps the meaning onto the structure. |
| value | A single number or piece of data. |
| variable | (coding): A word that identifies and stores the value of some data for later use; (stats): An attribute or characteristic of an observation that you can measure, count, or describe |
| wide | A data format where all of the observations about one subject are in the same row |
8.10 Further resources
- Data tidying cheat sheet
- Tidy Data
- Chapter 5: Tidy Data) in R for Data Science
- Chapter 4.3: Pipes in R for Data Science