7 Data Wrangling
Intended Learning Outcomes
Functions used
- built-in (you can always use these without loading any packages)
- base::
round(),mean(),min(),max(), `sum(),as.character(),as.numeric() - utils::
head(),packageVersion()
- base::
- tidyverse (you can use all these with
library(tidyverse))- readr::
readr::read_csv() - dplyr::
dplyr::filter(),dplyr::arrange(),dplyr::mutate(),dplyr::summarise(),dplyr::group_by(),dplyr::ungroup(),dplyr::case_when(),dplyr::na_if() - tidyr::
tidyr::pivot_longer(),tidyr::pivot_wider() - tibble::
tibble::tibble()
- readr::
- other (you need to load each package to use these)
- janitor::
janitor::round_half_up()
- janitor::
Set-up
- Open your
reproresproject - Create a new quarto file called
03-dataviz.qmd - Update the YAML header
- Replace the setup chunk with the one below:
At this point it’s very likely you will have the most recent version of the case_when() that we will use in this chapter was updated in to introduce new arguments and ways of handling NA. The code we provide in this chapter will only work if you have v1.1.0 or above of packageVersion("dplyr") and if it’s below 1.1.0, install it again to update.
You’ll need to make a folder called “data” and download a data file into it: budget.csv.
Download the Data transformation cheat sheet.
7.1 Wrangling functions
Data wrangling refers to the process of cleaning, transforming, and restructuring your data to get it into the format you need for analysis and it’s something you will spend an awful lot of time doing. Most data wrangling involves the reshaping functions you learned in Chapter 6 and six functions from the select, filter, arrange, mutate, summarise, and group_by. You’ll remember the last two from Chapter 4, so we’ll only cover them briefly.
It’s worth highlighting that in this chapter we’re going to cover these common functions and common uses of said functions. However,
We’ll use a small example table with the sales, expenses, and satisfaction for two years from four regions over two products. After you load the data, use glimpse(budget) or View(budget) to get familiar with the data.
| region | product | sales_2019 | sales_2020 | expenses_2019 | expenses_2020 | satisfaction_2019 | satisfaction_2020 |
|---|---|---|---|---|---|---|---|
| North | widgets | 2129 | -517 | 822 | -897 | high | very high |
| North | gadgets | 723 | 77 | 1037 | 1115 | very high | very high |
| South | widgets | 1123 | -1450 | 1004 | 672 | high | neutral |
| South | gadgets | 2022 | -945 | -610 | 200 | low | low |
| East | widgets | -728 | -51 | -801 | -342 | very low | very low |
| East | gadgets | -423 | -354 | 94 | 2036 | neutral | high |
| West | widgets | 633 | 790 | 783 | -315 | neutral | neutral |
| West | gadgets | 1204 | 426 | 433 | -136 | low | low |
7.1.1 Select
You can select a subset of the columns (variables) in a table to make it easier to view or to prepare a table for display. You can also select columns in a new order.
7.1.1.1 By name or index
You can select columns by name or number (which is sometimes referred to as the column index). Selecting by number can be useful when the column names are long or complicated.
You can select each column individually, separated by commas (e.g., region, sales_2019) but you can also select all columns from one to another by separating them with a colon (e.g., sales_2019:expenses_2020).
The colon notation can be much faster because you don’t need to type out each individual variable name, but requires you know what order your columns are in and don’t expect them to change. Always check the output to make sure you have selected what you intended.
You can rename columns at the same time as selecting them by setting new_name = old_col.
7.1.1.2 Un-selecting columns
You can select columns either by telling R which ones you want to keep as in the previous examples, or by specifying which ones you want to exclude by using a minus symbol to un-select columns. You can also use the colon notation to de-select columns, but to do so you need to put parentheses around the span first, e.g., -(sales_2019:expenses_2020), not -sales_2019:expenses_2020.
7.1.1.3 Select helpers
Finally, you can select columns based on criteria about the column names.
| function | definition |
|---|---|
starts_with() |
select columns that start with a character string |
ends_with() |
select columns that end with a character string |
contains() |
select columns that contain a character string |
num_range() |
select columns with a name that matches the pattern prefix
|
What are the resulting columns for these four examples?
-
budget |> select(contains("_")) -
budget |> select(num_range("expenses_", 2019:2020)) -
budget |> select(starts_with("sales")) -
budget |> select(ends_with("2020"))
7.1.2 Filter
Whilst select() chooses the columns you want to retain, filter() chooses the rows to retain by matching row or column criteria.
You can filter by a single criterion. This criterion can be rows where a certain column’s value matches a character value (e.g., “North”) or a number (e.g., 9003). It can also be the result of a logical equation (e.g., keep all rows with a specific column value larger than a certain value). The criterion is checked for each row, and if the result is FALSE, the row is removed. You can reverse equations by specifying != where ! means “not”.
# select all rows where region equals North
budget |> filter(region == "North")
# select all rows where expenses_2020 were exactly equal to 200
budget |> filter(expenses_2020 == 200)
# select all rows where sales_2019 was more than 100
budget |> filter(sales_2019 > 100)
# everything but the North
budget |> filter(region != "North")Remember to use == and not = to check if two things are equivalent. A single = assigns the right-hand value to the left-hand variable (much like the <- operator).
Which IDs are kept from the table below?
| id | grade | score |
|---|---|---|
| 1 | A | 95 |
| 2 | A | 91 |
| 3 | C | 76 |
| 4 | B | 84 |
-
demo |> filter(score < 80) -
demo |> filter(grade == "A") -
demo |> filter(grade != "A") -
demo |> filter(score == 91)
You can also select on multiple criteria by separating them by commas (rows will be kept if they match all criteria). Additionally, you can use & (“and”) and | (“or”) to create complex criteria.
# regions and products with profit in both 2019 and 2020
profit_both <- budget |>
filter(
sales_2019 > expenses_2019,
sales_2020 > expenses_2020
)
# the same as above, using & instead of a comma
profit_both <- budget |>
filter(
sales_2019 > expenses_2019 &
sales_2020 > expenses_2020
)
# regions and products with profit in 2019 or 2020
profit_either <- budget |>
filter(
sales_2019 > expenses_2019 |
sales_2020 > expenses_2020
)
# 2020 profit greater than 1000
profit_1000 <- budget |>
filter(sales_2020 - expenses_2020 > 1000)If you want the filter to retain multiple specific values in the same variable, the “match operator” (%in%) should be used rather than | (or). The ! can also be used in combination here, but it is placed before the variable name.
# retain any rows where region is north or south, and where product equals widget
budget |>
filter(region %in% c("North", "South"),
product == "widgets")
# retain any rows where the region is not east or west, and where the product does not equal gadgets
budget |>
filter(!region %in% c("East", "West"),
product != "gadgets")| Operator | Name | is TRUE if and only if |
|---|---|---|
A < B |
less than | A is less than B |
A <= B |
less than or equal | A is less than or equal to B |
A > B |
greater than | A is greater than B |
A >= B |
greater than or equal | A is greater than or equal to B |
A == B |
equivalence | A exactly equals B |
A != B |
not equal | A does not exactly equal B |
A %in% B |
in | A is an element of vector B |
Finally, you can also pass many other functions to filter. For example, the package str_detect() to only retain rows where the customer satisfaction rating includes the word “high”
| region | product | sales_2019 | sales_2020 | expenses_2019 | expenses_2020 | satisfaction_2019 | satisfaction_2020 |
|---|---|---|---|---|---|---|---|
| North | widgets | 2129 | -517 | 822 | -897 | high | very high |
| North | gadgets | 723 | 77 | 1037 | 1115 | very high | very high |
| South | widgets | 1123 | -1450 | 1004 | 672 | high | neutral |
Note that str_detect() is case sensitive so it would not return values of “High” or “HIGH”. You can use the function tolower() or toupper() to convert a string to lowercase or uppercase before you search for substring if you need case-insensitive matching.
filter() is incredibly powerful and can allow you to select very specific subsets of data. But, it is also quite dangerous because when you start combining multiple criteria and operators, it’s very easy to accidentally specify something slightly different than what you intended. Always check your output. If you have a small dataset, then you can eyeball it to see if it looks right. With a larger dataset, you may wish to compute summary statistics or count the number of groups/observations in each variable to verify your filter is correct. There is no level of expertise in coding that can substitute knowing and checking your data.
7.1.3 Arrange
You can sort your dataset using arrange(). You will find yourself needing to sort data in R much less than you do in Excel, since you don’t need to have rows next to each other in order to, for example, calculate group means. But arrange() can be useful when preparing data for display in tables. arrange() works on character data where it will sort alphabetically, as well as numeric data where the default is ascending order (smallest to largest). Reverse the order using desc().
# arranging the table
# first by product in alphabetical order
# then by "region" in reverse alphabetical order
budget |>
arrange(product, desc(region))| region | product | sales_2019 | sales_2020 | expenses_2019 | expenses_2020 | satisfaction_2019 | satisfaction_2020 |
|---|---|---|---|---|---|---|---|
| West | gadgets | 1204 | 426 | 433 | -136 | low | low |
| South | gadgets | 2022 | -945 | -610 | 200 | low | low |
| North | gadgets | 723 | 77 | 1037 | 1115 | very high | very high |
| East | gadgets | -423 | -354 | 94 | 2036 | neutral | high |
| West | widgets | 633 | 790 | 783 | -315 | neutral | neutral |
| South | widgets | 1123 | -1450 | 1004 | 672 | high | neutral |
| North | widgets | 2129 | -517 | 822 | -897 | high | very high |
| East | widgets | -728 | -51 | -801 | -342 | very low | very low |
If you want to sort character data/categories in a specific order, turn the column into a factor and set the levels in the desired order.
budget |>
mutate(region = factor(region, levels = c("North", "South", "East", "West"))) |>
filter(product == "gadgets") |>
arrange(region)| region | product | sales_2019 | sales_2020 | expenses_2019 | expenses_2020 | satisfaction_2019 | satisfaction_2020 |
|---|---|---|---|---|---|---|---|
| North | gadgets | 723 | 77 | 1037 | 1115 | very high | very high |
| South | gadgets | 2022 | -945 | -610 | 200 | low | low |
| East | gadgets | -423 | -354 | 94 | 2036 | neutral | high |
| West | gadgets | 1204 | 426 | 433 | -136 | low | low |
7.1.4 Mutate
The function mutate() allows you to add new columns or change existing ones by overwriting them by using the syntax new_column = operation. You can add more than one column in the same mutate function by separating the columns with a comma. Once you make a new column, you can use it in further column definitions. For example, the creation of profit below uses the column expenses, which is created above it.
mutate() can also be used in conjunction with other functions and Boolean operators. For example, we can add another column to budget2 that states whether a profit was returned that year or overwrite our product variable as a factor. Just like when we used Boolean expressions with filter, it will evaluate the equation and return TRUE or FALSE depending on whether the observation meets the criteria.
You can overwrite a column by giving a new column the same name as the old column (see region or product) above. Make sure that you mean to do this and that you aren’t trying to use the old column value after you redefine it.
You can also use case_when() to specify what values to return, rather than defaulting to TRUE or FALSE:
Use it to recode values:
And combine different criteria:
# new management takes over - people only get a bonus if customer satisfaction was overall high or very high AND if a profit was returned
bonus2 <- budget3 |>
mutate(bonus_2020 = case_when(satisfaction_2020 == "high" &
profit_category == "PROFIT" ~ "bonus",
satisfaction_2020 == "very high" &
profit_category == "PROFIT" ~ "bonus",
.default = "No bonus")) # set all other values to "no bonus"Be mindful that .default uses = whilst the others use ~. Emily has lost quite a lot of her time and sanity to not realising this.
Just like filter(), mutate() is incredibly powerful and the scope of what you can create is far beyond what we can cover in this book.
7.1.5 Summarise
You were introduced to the summarise() function in Section 4.4. This applies summary functions to an entire table (or groups, as you’ll see in the next section).
Let’s say we want to determine the mean sales and expenses, plus the minimum and maximum profit, for any region, product and year. First, we need to reshape the data like we learned in Chapter 6, so that there is a column for year and one column each for sales and expenses, instead of separate columns for each year. We’ll also drop the satisfaction data as we don’t need it for this analysis.
budget4 <- budget |>
select(-satisfaction_2019, -satisfaction_2020) |>
pivot_longer(cols = sales_2019:expenses_2020,
names_to = c("type", "year"),
names_sep = "_",
names_transform = list(year = as.integer),
values_to = "value") |>
pivot_wider(names_from = type,
values_from = value)
head(budget4) # check the format| region | product | year | sales | expenses |
|---|---|---|---|---|
| North | widgets | 2019 | 2129 | 822 |
| North | widgets | 2020 | -517 | -897 |
| North | gadgets | 2019 | 723 | 1037 |
| North | gadgets | 2020 | 77 | 1115 |
| South | widgets | 2019 | 1123 | 1004 |
| South | widgets | 2020 | -1450 | 672 |
Now we can create summary statistics for the table.
7.1.6 Group By
You were introduced to the group_by() function in Section 4.5. For example, you can break down the summary statistics above by year and product.
year_prod <- budget4 |>
group_by(year, product) |>
summarise(
mean_sales = mean(sales),
mean_expenses = mean(expenses),
min_profit = min(expenses - sales),
max_profit = max(expenses - sales)
) |>
ungroup()
year_prod| year | product | mean_sales | mean_expenses | min_profit | max_profit |
|---|---|---|---|---|---|
| 2019 | gadgets | 881.50 | 238.50 | -2632 | 517 |
| 2019 | widgets | 789.25 | 452.00 | -1307 | 150 |
| 2020 | gadgets | -199.00 | 803.75 | -562 | 2390 |
| 2020 | widgets | -307.00 | -220.50 | -1105 | 2122 |
Alternatively, if you have a newer version of tidyverse, you can use the .by argument to summarise by groups.
budget4 |>
summarise(
.by = c(year, product),
mean_sales = mean(sales),
mean_expenses = mean(expenses),
min_profit = min(expenses - sales),
max_profit = max(expenses - sales)
)| year | product | mean_sales | mean_expenses | min_profit | max_profit |
|---|---|---|---|---|---|
| 2019 | widgets | 789.25 | 452.00 | -1307 | 150 |
| 2020 | widgets | -307.00 | -220.50 | -1105 | 2122 |
| 2019 | gadgets | 881.50 | 238.50 | -2632 | 517 |
| 2020 | gadgets | -199.00 | 803.75 | -562 | 2390 |
How would you find out the maximum sales for each region?
You can also use group_by() in combination with other functions. For example, slice_max() returns the top N rows, ordered by a specific variable.
| region | product | year | sales | expenses |
|---|---|---|---|---|
| North | widgets | 2019 | 2129 | 822 |
| South | gadgets | 2019 | 2022 | -610 |
| West | gadgets | 2019 | 1204 | 433 |
But this can be combined with group_by() to return the top sales for each region:
7.2 Complications
7.2.1 Rounding
Let’s say we want to round all the values to the nearest pound. The pattern below uses the across() function to apply the round() function to the columns from mean_sales to max_profit.
| year | product | mean_sales | mean_expenses | min_profit | max_profit |
|---|---|---|---|---|---|
| 2019 | gadgets | 882 | 238 | -2632 | 517 |
| 2019 | widgets | 789 | 452 | -1307 | 150 |
| 2020 | gadgets | -199 | 804 | -562 | 2390 |
| 2020 | widgets | -307 | -220 | -1105 | 2122 |
If you compare this table to the one in Section 7.1.6, you’ll see that the 2019 gadgets mean sales rounded up from 881.5 to 882, while the mean expenses rounded down from 238.5 to 238. What’s going on!?
This may seem like a mistake, but R rounds .5 to the nearest even number, rather than always up, like you were probably taught in school. This prevents overestimation biases, since x.5 is exactly halfway between x and x+1, so there is no reason it should always round up.
However, this might throw a monkey wrench into your own systems. For example, our school policy is to round up for course marks at x.5. The easiest solution is to use the round_half_up() function from the package
when you run this code, a new section will appear in the environment pane labelled “Functions”. In addition to using functions from packages, you can also make your own. It’s not something we are going to go into detail on in this course, but it’s useful to know the functionality exists.
This should work as you’d expect.
7.2.2 Missing values
If you have control over your data, it is always best to keep missing values as empty cells rather than denoting missingness with a word or implausible number. If you used “missing” rather than leaving the cell empty, the entire variable would be read as character data (unless you note this on import), which means you wouldn’t be able to perform mathematical operations like calculating the mean. If you use an implausible number (0 or 999 are common), then you risk these values being included in any calculations as real numbers.
However, we often don’t have control over how the data come to us, so let’s run through how to fix this.
7.2.2.1 Bad missing values
What if the South region hadn’t returned their expenses (entered as 0) and the North region hadn’t returned their sales data for 2020 yet, so someone entered it as “missing”?
First, we’re going to recode the data to add in the missing values
For the South data, we can use case_when() to set the value of expenses to 0 if the year is 2020 and region is “South”, otherwise use the value from the expenses column (i.e., don’t change).
The case_when() function allows allows you to set multiple criteria, although we’re only using one non-default criterion here. It can be very useful, but takes a little practice.
The example below creates a label for each row. Notice how the label for the first row is “x < 2”, even though this row also fits the second criterion “y < 4”. This is because case_when() applies the first match to each row, even if other criteria in the function also match that row.
For the North, we will recode these values as “missing”. Since this is character data, and sales are currently numeric data, we first need to change it to a character variable.
# set sales values to "missing" for North 2020 rows
missing_bad <- missing_bad |>
mutate(sales = as.character(sales), # Convert all sales to character
sales = case_when(year == 2020 & region == "North" ~ "missing",
TRUE ~ sales)) # Set specific condition to "missing"
str(missing_bad)tibble [16 × 5] (S3: tbl_df/tbl/data.frame)
$ region : chr [1:16] "North" "North" "North" "North" ...
$ product : chr [1:16] "widgets" "widgets" "gadgets" "gadgets" ...
$ year : int [1:16] 2019 2020 2019 2020 2019 2020 2019 2020 2019 2020 ...
$ sales : chr [1:16] "2129" "missing" "723" "missing" ...
$ expenses: num [1:16] 822 -897 1037 1115 1004 ...Now, if you try to compute the mean sales, you will get an error message and the result will be NA.
7.2.2.2 Convert missing values to NA
To set the missing values to NA, we can use the handy function na_if(). We’ll also need to transform sales back to numeric.
Now, if we try to calculate the mean sales and profits, we get missing values for any summary value that used one of the North 2020 sales values or the South 2020 expenses.
missing_data |>
group_by(region) |>
summarise(
mean_sales = mean(sales),
mean_expenses = mean(expenses),
min_profit = min(expenses - sales),
max_profit = max(expenses - sales),
.groups = "drop")| region | mean_sales | mean_expenses | min_profit | max_profit |
|---|---|---|---|---|
| East | -389.00 | 246.75 | -291 | 2390 |
| North | NA | 519.25 | NA | NA |
| South | 187.50 | NA | NA | NA |
| West | 763.25 | 191.25 | -1105 | 150 |
7.2.2.3 Ignore missing values
This is because NA basically means “I don’t know”, and the sum of 100 and “I don’t know” is “I don’t know”, not 100. However, when you’re calculating means, you often want to just ignore missing values. Set na.rm = TRUE in the summary function to remove missing values before calculating.
missing_data |>
group_by(region) |>
summarise(
mean_sales = mean(sales, na.rm = TRUE),
mean_expenses = mean(expenses, na.rm = TRUE),
min_profit = min(expenses - sales, na.rm = TRUE),
max_profit = max(expenses - sales, na.rm = TRUE),
.groups = "drop"
)| region | mean_sales | mean_expenses | min_profit | max_profit |
|---|---|---|---|---|
| East | -389.00 | 246.75 | -291 | 2390 |
| North | 1426.00 | 519.25 | -1307 | 314 |
| South | 187.50 | 197.00 | -2632 | -119 |
| West | 763.25 | 191.25 | -1105 | 150 |
7.2.2.4 Count missing values
If you want to find out how many missing or non-missing values there are in a column, use the is.na() function to get a logical vector of whether or not each value is missing, and use sum() to count how many values are TRUE or mean() to calculate the proportion of TRUE values.
missing_data |>
group_by(year, product) |>
summarise(
n_valid = sum(!is.na(sales)),
n_missing = sum(is.na(sales)),
prop_missing = mean(is.na(sales)),
.groups = "drop"
)| year | product | n_valid | n_missing | prop_missing |
|---|---|---|---|---|
| 2019 | gadgets | 4 | 0 | 0.00 |
| 2019 | widgets | 4 | 0 | 0.00 |
| 2020 | gadgets | 3 | 1 | 0.25 |
| 2020 | widgets | 3 | 1 | 0.25 |
7.2.2.5 Omit missing values
You may also want to remove rows that have missing values and only work from complete datasets. drop_na() will remove any row that has a missing observation. You can use drop_na() on the entire dataset which will remove any row that has any missing value, or you can specify to only remove rows that are missing a specific value.
Missing data can be quite difficult to deal with depending on how it is represented. As always, no amount of coding expertise can make up for not understanding the structure and idiosyncrasies of your data.
7.3 Exercises
Let’s try some exercises using a dataset you already encountered in Chapter 3 so that you can see how much more you’re able to do with the data now.
- Save your current script, close it, and open a new script named “survey-data-mad-skillz.qmd”.
- In the set-up code chunk, load the tidyverse, then load the dataset from https://psyteachr.github.io/ads-v2/data/survey_data.csv into an object named
survey_data. - Use your method of choice to review the dataset and familiarise yourself with its structure.
7.3.1 Creating new categories
Employees 1-5 were trained by Michael and employees 6-10 were trained by Dwight.
- Create a new column named
trainerthat lists the trainer for each employee. - Then, calculate the average satisfaction scores for employees trained by each trainer and visualise the satisfaction scores for each in whatever way you think best.
r hide("Hint") To add the trainer column you can use case_when() and specify multiple criteria (e.g., if the employee is 1-5, Michael, if the employee is 6-10 Dwight) r unhide()
# case_when() method
survey_data <- survey_data |>
mutate(trainer = case_when(employee_id %in% c("E01", "E02", "E03", "E04", "E05") ~ "Michael",
employee_id %in% c("E06", "E07", "E08", "E09", "E10") ~ "Dwight"))
# mean satisfaction scores
survey_data |>
group_by(trainer) |>
summarise(mean_satisfaction = mean(satisfaction))
# possible visualisation
ggplot(survey_data, aes(x = satisfaction, fill = trainer)) +
geom_histogram(binwidth = 1, show.legend = FALSE, colour = "black") +
facet_wrap(~trainer) +
labs(title = "Satisfaction scores by employee trainer")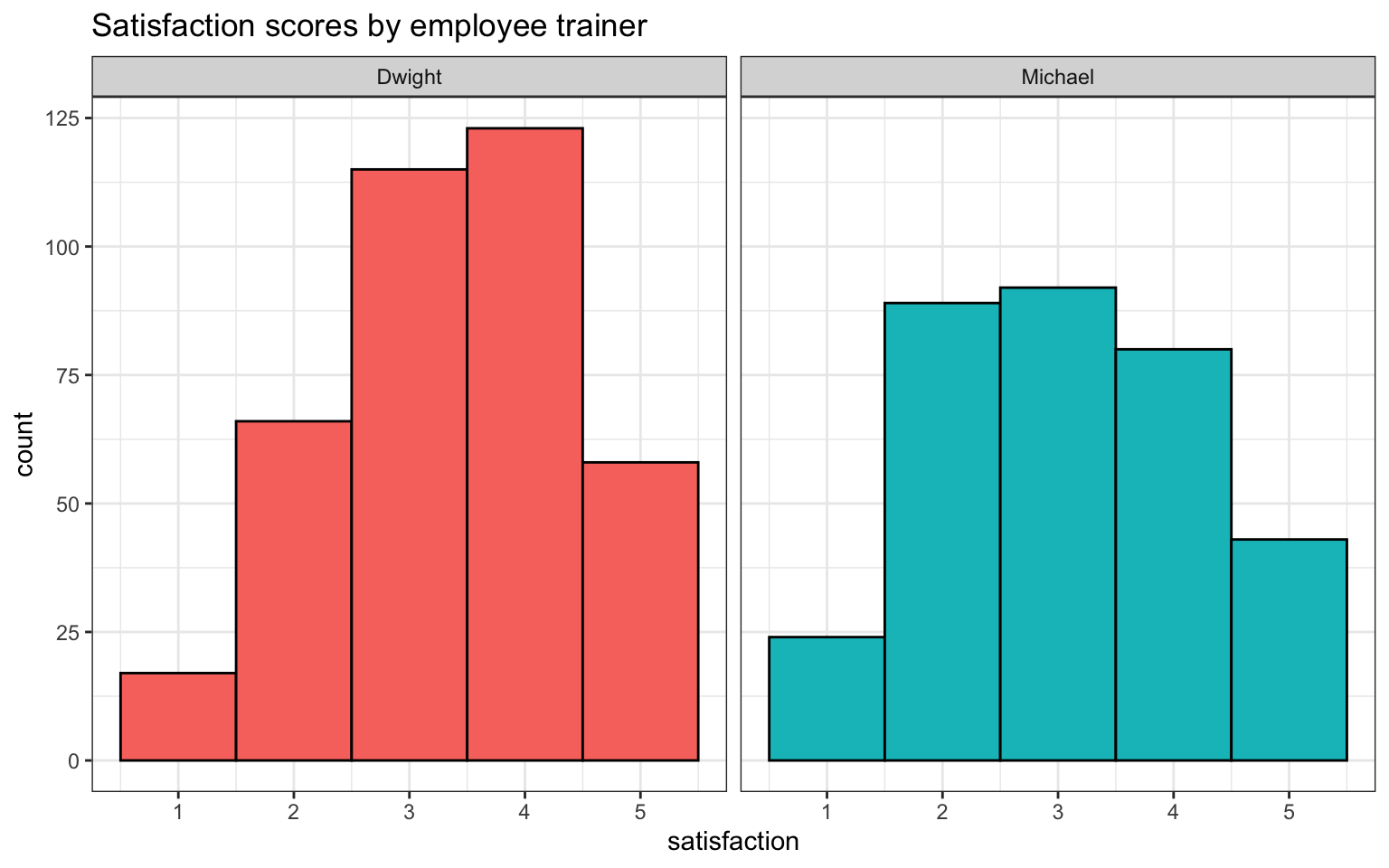
| trainer | mean_satisfaction |
|---|---|
| Dwight | 3.366755 |
| Michael | 3.088415 |
7.3.2 Filter by calculated score
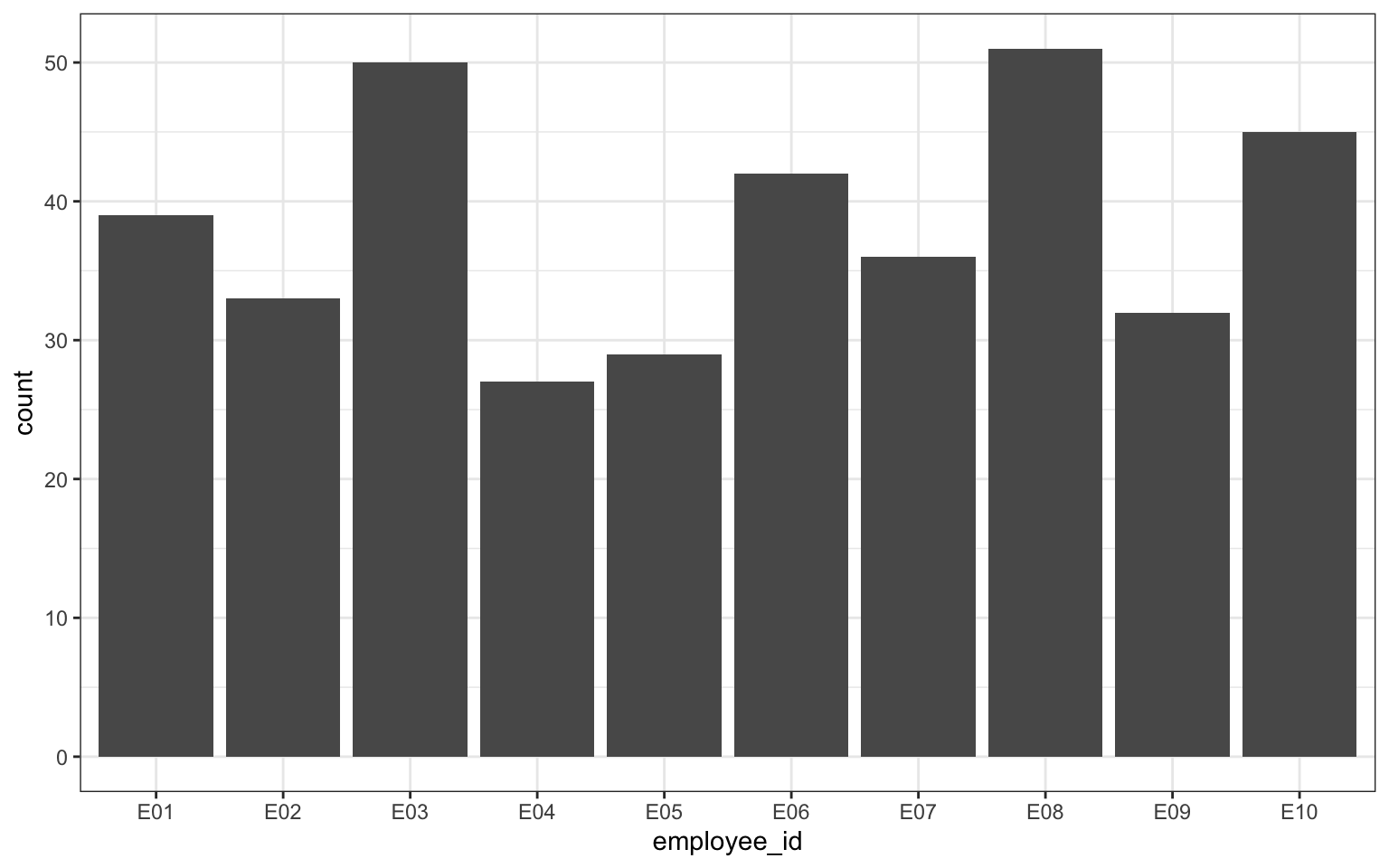
First, calculate the average wait time and store this in an object named mean_wait. This should be a single value rather than a table.
There are multiple ways to achieve this. You could create the table and then pull out the single value, or just calculate the single value.
Now create a dataset named long_wait that just contains data from customers who waited more than the average wait time.
Create a visualisation that shows how many customers waited more than the average wait time for each employee.
7.3.3 Multiple critera
Now, add a column to survey_data named follow_up that flags whether a customer should be followed up with a courtesy phone call. Your company is short-staffed so only customers that meet all three of the following criteria should be followed-up:
- Their wait time should be above the average for all calls
- Their call time should be above the average for their category
- Their satisfaction should be less than three 3.
This is quite complicated and there are multiple ways to achieve the desired outcome. Some approaches may need other functions that were covered in previous chapters and you may need to create intermediate objects.
Call the final object follow_data and keep only the customer ID, employee ID, trainer, and follow up columns.
# this is one possible solution, there are many other valid approaches
# calculate mean wait time across all calls
mean_wait <- mean(survey_data$wait_time)
# calculate mean call time for each category
follow_data <- survey_data |>
group_by(issue_category) |>
summarise(mean_call = mean(call_time)) |>
#then join it to the survey data
left_join(survey_data, by = "issue_category") |>
# then add on the column
mutate(follow_up = case_when(wait_time > mean_wait &
call_time > mean_call &
satisfaction < 3 ~ "yes",
.default = "no")) |>
select(caller_id, employee_id, trainer, follow_up)For all of the above, write code that stores the answer as a single value, so that you could easily use it in inline coding.
How many customers need to be followed up:
- In total?
- From calls by employee 06?
- From calls by employees trained by Michael
- From calls by employees trained by Dwight
group_by() |> count() |> filter() |> pull()
Which employee needs to make the largest number of follow-up courtesy calls?
As above but add in an ungroup() and slice_max() along the way.
# in total
follow_data |>
group_by(follow_up) |>
count()|>
filter(follow_up == "yes") |>
pull(n)
# by employee 6
follow_data |>
group_by(follow_up, employee_id) |>
count() |>
filter(employee_id == "E06",
follow_up == "yes") |>
pull(n)
# by michael
follow_data |>
group_by(follow_up, trainer) |>
count() |>
filter(trainer == "Michael",
follow_up == "yes") |>
pull(n)
# by dwight
follow_data |>
group_by(follow_up, trainer) |>
count() |>
filter(trainer == "Dwight",
follow_up == "yes") |>
pull(n)
# most follow-ups needed
follow_data |>
group_by(follow_up, employee_id) |>
count() |>
ungroup() |>
filter(follow_up == "yes") |>
slice_max(n = 1, order_by = n) |>
pull(employee_id)[1] 120
[1] 16
[1] 65
[1] 55
[1] "E02"7.3.4 Original insight
In preparation for the summative assessment, explore the data to provide one original insight of your own.
Glossary
| term | definition |
|---|---|
| boolean-expression | An expression that evaluates to TRUE or FALSE. |
| character | A data type representing strings of text. |
| data-type | The kind of data represented by an object. |
| data-wrangling | The process of preparing data for visualisation and statistical analysis. |
| factor | A data type where a specific set of values are stored with labels; An explanatory variable manipulated by the experimenter |
| logical | A data type representing TRUE or FALSE values. |
| operator | A symbol that performs some mathematical or comparative process. |
| string | A piece of text inside of quotes. |
Further resources
- Data transformation cheat sheet
- Chapter 18: Missing Data in R for Data Science
- Chapter 3: Data Transformation in R for Data Science
- Chapter 25: Functions in R for Data Science
- Introduction to stringr