Chapter 9 Introduction to GLM

9.1 Learning Objectives
9.1.1 Basic
- Define the components of the GLM
- Simulate data using GLM equations (video)
- Identify the model parameters that correspond to the data-generation parameters
- Understand and plot residuals (video)
- Predict new values using the model (video)
- Explain the differences among coding schemes (video)
9.1.2 Intermediate
- Demonstrate the relationships among two-sample t-test, one-way ANOVA, and linear regression
- Given data and a GLM, generate a decomposition matrix and calculate sums of squares, mean squares, and F ratios for a one-way ANOVA
9.2 Resources
9.3 Setup
# libraries needed for these examples
library(tidyverse)
library(broom)
set.seed(30250) # makes sure random numbers are reproducible9.4 GLM
9.4.1 What is the GLM?
The General Linear Model (GLM) is a general mathematical framework for expressing relationships among variables that can express or test linear relationships between a numerical dependent variable and any combination of categorical or continuous independent variables.
9.4.2 Components
There are some mathematical conventions that you need to learn to understand the equations representing linear models. Once you understand those, learning about the GLM will get much easier.
| Component of GLM | Notation |
|---|---|
| Dependent Variable (DV) | \(Y\) |
| Grand Average | \(\mu\) (the Greek letter “mu”) |
| Main Effects | \(A, B, C, \ldots\) |
| Interactions | \(AB, AC, BC, ABC, \ldots\) |
| Random Error | \(S(Group)\) |

The linear equation predicts the dependent variable (\(Y\)) as the sum of the grand average value of \(Y\) (\(\mu\), also called the intercept), the main effects of all the predictor variables (\(A+B+C+ \ldots\)), the interactions among all the predictor variables (\(AB, AC, BC, ABC, \ldots\)), and some random error (\(S(Group)\)). The equation for a model with two predictor variables (\(A\) and \(B\)) and their interaction (\(AB\)) is written like this:
\(Y\) ~ \(\mu+A+B+AB+S(Group)\)
Don’t worry if this doesn’t make sense until we walk through a concrete example.
9.4.3 Simulating data from GLM
A good way to learn about linear models is to simulate data where you know exactly how the variables are related, and then analyse this simulated data to see where the parameters show up in the analysis.
We’ll start with a very simple linear model that just has a single categorical factor with two levels. Let’s say we’re predicting reaction times for congruent and incongruent trials in a Stroop task for a single participant. Average reaction time (mu) is 800ms, and is 50ms faster for congruent than incongruent trials (effect).
A factor is a categorical variable that is used to divide subjects into groups, usually to draw some comparison. Factors are composed of different levels. Do not confuse factors with levels!
In the example above, trial type is a , incongrunt is a , and congruent is a .
You need to represent categorical factors with numbers. The numbers, or coding scheme you choose will affect the numbers you get out of the analysis and how you need to interpret them. Here, we will effect code the trial types so that congruent trials are coded as +0.5, and incongruent trials are coded as -0.5.
A person won’t always respond exactly the same way. They might be a little faster on some trials than others, due to random fluctuations in attention, learning about the task, or fatigue. So we can add an error term to each trial. We can’t know how much any specific trial will differ, but we can characterise the distribution of how much trials differ from average and then sample from this distribution.
Here, we’ll assume the error term is sampled from a normal distribution with a standard deviation of 100 ms (the mean of the error term distribution is always 0). We’ll also sample 100 trials of each type, so we can see a range of variation.
So first create variables for all of the parameters that describe your data.
n_per_grp <- 100
mu <- 800 # average RT
effect <- 50 # average difference between congruent and incongruent trials
error_sd <- 100 # standard deviation of the error term
trial_types <- c("congruent" = 0.5, "incongruent" = -0.5) # effect codeThen simulate the data by creating a data table with a row for each trial and columns for the trial type and the error term (random numbers samples from a normal distribution with the SD specified by error_sd). For categorical variables, include both a column with the text labels (trial_type) and another column with the coded version (trial_type.e) to make it easier to check what the codings mean and to use for graphing. Calculate the dependent variable (RT) as the sum of the grand mean (mu), the coefficient (effect) multiplied by the effect-coded predictor variable (trial_type.e), and the error term.
dat <- data.frame(
trial_type = rep(names(trial_types), each = n_per_grp)
) %>%
mutate(
trial_type.e = recode(trial_type, !!!trial_types),
error = rnorm(nrow(.), 0, error_sd),
RT = mu + effect*trial_type.e + error
)
The !!! (triple bang) in the code recode(trial_type, !!!trial_types) is a way to expand the vector trial_types <- c(“congruent” = 0.5, “incongruent” = -0.5). It’s equivalent to recode(trial_type, “congruent” = 0.5, “incongruent” = -0.5). This pattern avoids making mistakes with recoding because there is only one place where you set up the category to code mapping (in the trial_types vector).
Last but not least, always plot simulated data to make sure it looks like you expect.
ggplot(dat, aes(trial_type, RT)) +
geom_violin() +
geom_boxplot(aes(fill = trial_type),
width = 0.25, show.legend = FALSE)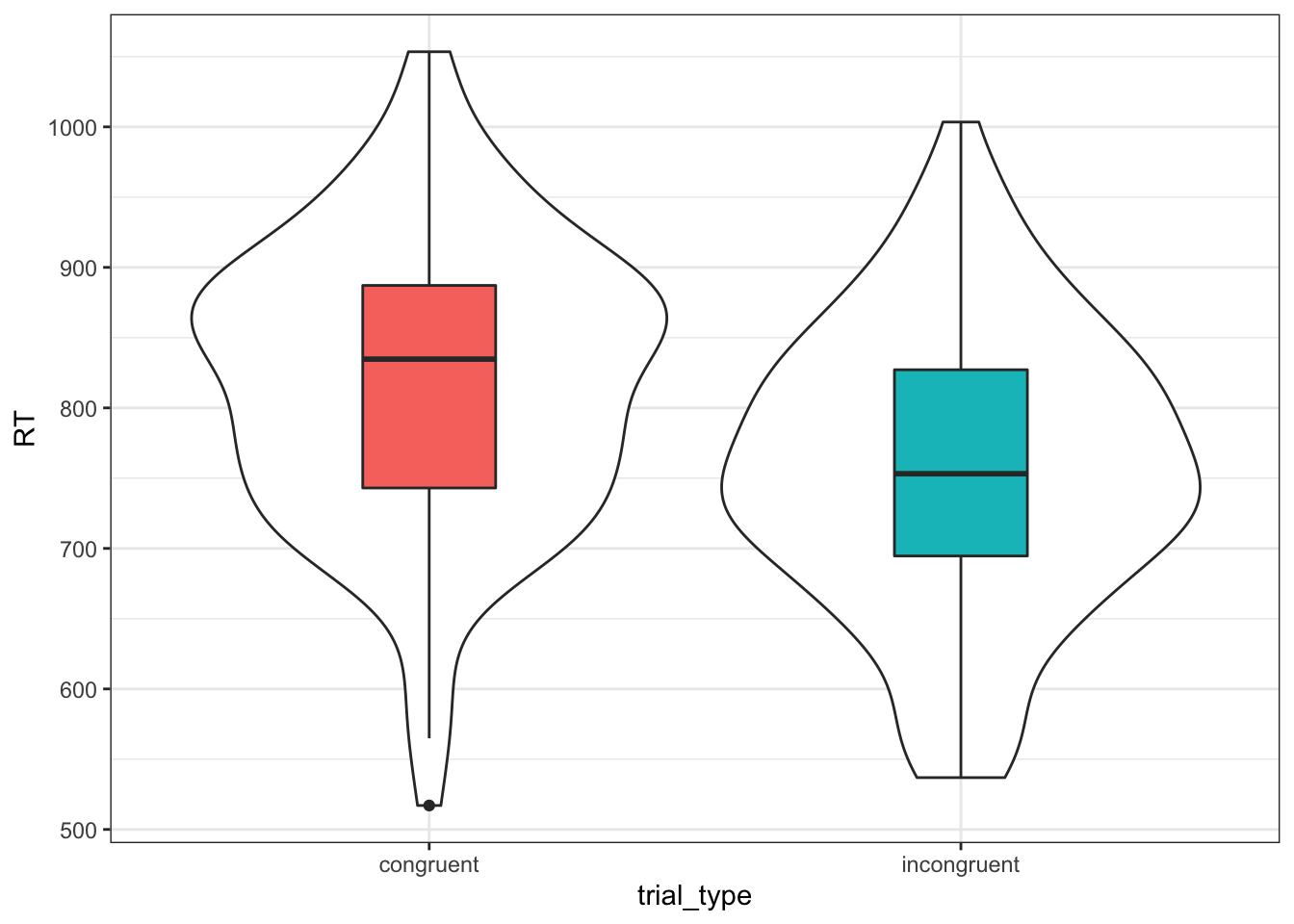
Figure 9.1: Simulated Data
9.4.4 Linear Regression
Now we can analyse the data we simulated using the function lm(). It takes the formula as the first argument. This is the same as the data-generating equation, but you can omit the error term (this is implied), and takes the data table as the second argument. Use the summary() function to see the statistical summary.
my_lm <- lm(RT ~ trial_type.e, data = dat)
summary(my_lm)##
## Call:
## lm(formula = RT ~ trial_type.e, data = dat)
##
## Residuals:
## Min 1Q Median 3Q Max
## -302.110 -70.052 0.948 68.262 246.220
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 788.192 7.206 109.376 < 2e-16 ***
## trial_type.e 61.938 14.413 4.297 2.71e-05 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 101.9 on 198 degrees of freedom
## Multiple R-squared: 0.08532, Adjusted R-squared: 0.0807
## F-statistic: 18.47 on 1 and 198 DF, p-value: 2.707e-05Notice how the estimate for the (Intercept) is close to the value we set for mu and the estimate for trial_type.e is close to the value we set for effect.
Change the values of mu and effect, resimulate the data, and re-run the linear model. What happens to the estimates?
9.4.5 Residuals
You can use the residuals() function to extract the error term for each each data point. This is the DV values, minus the estimates for the intercept and trial type. We’ll make a density plot of the residuals below and compare it to the normal distribution we used for the error term.
res <- residuals(my_lm)
ggplot(dat) +
stat_function(aes(0), color = "grey60",
fun = dnorm, n = 101,
args = list(mean = 0, sd = error_sd)) +
geom_density(aes(res, color = trial_type))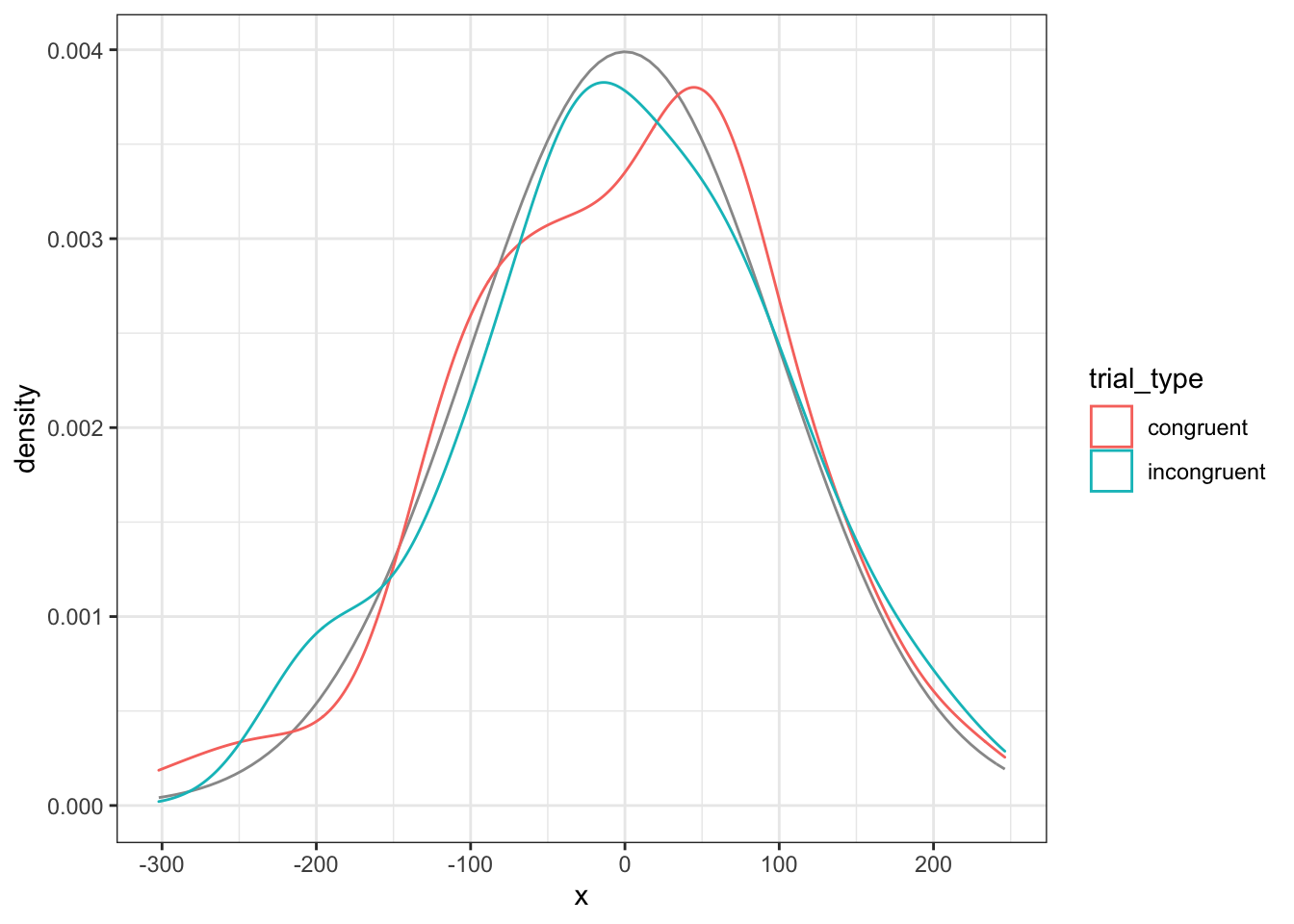
Figure 9.2: Model residuals should be approximately normally distributed for each group
You can also compare the model residuals to the simulated error values. If the model is accurate, they should be almost identical. If the intercept estimate is slightly off, the points will be slightly above or below the black line. If the estimate for the effect of trial type is slightly off, there will be a small, systematic difference between residuals for congruent and incongruent trials.
ggplot(dat) +
geom_abline(slope = 1) +
geom_point(aes(error, res,color = trial_type)) +
ylab("Model Residuals") +
xlab("Simulated Error")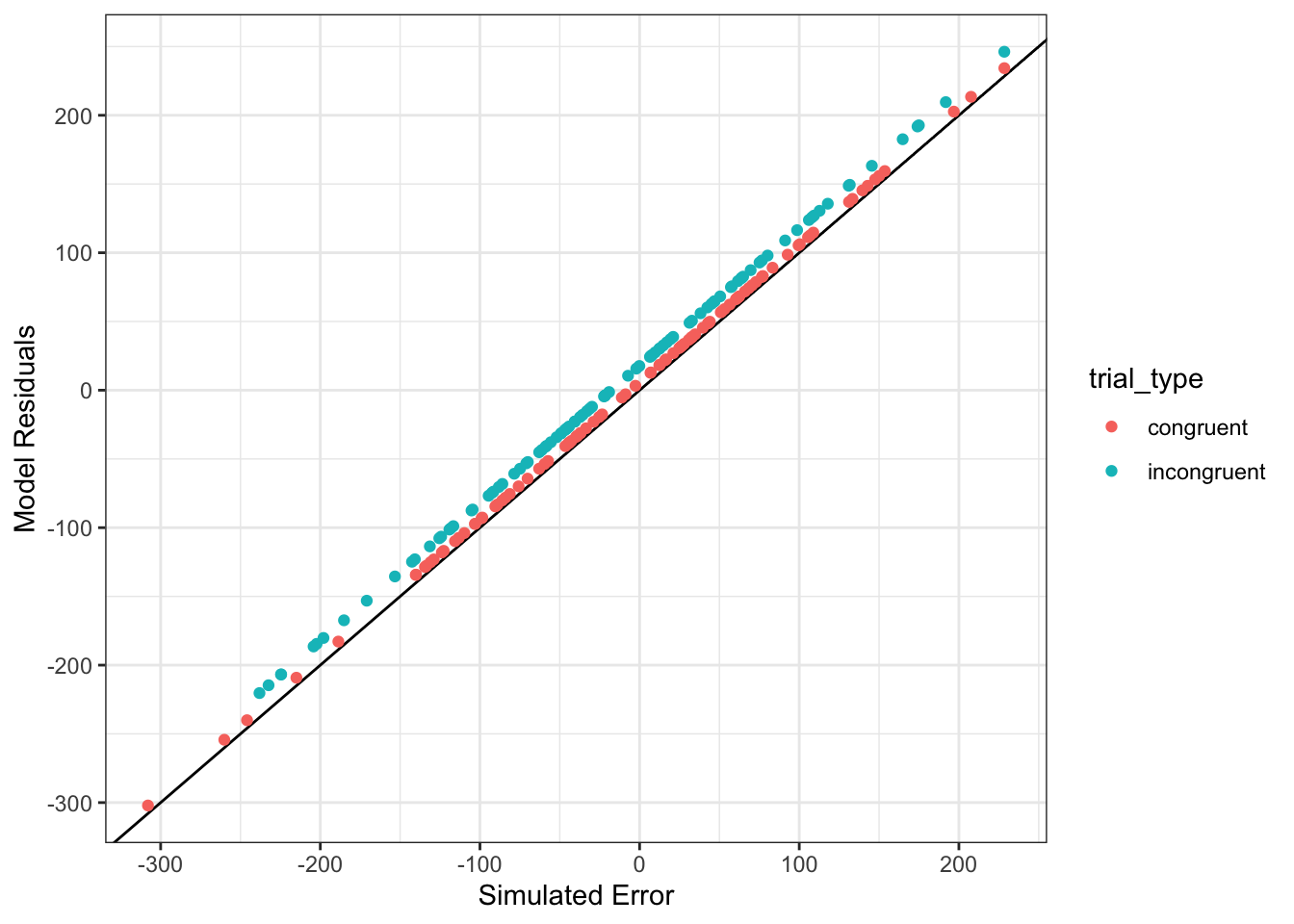
Figure 9.3: Model residuals should be very similar to the simulated error
What happens to the residuals if you fit a model that ignores trial type (e.g., lm(Y ~ 1, data = dat))?
9.4.6 Predict New Values
You can use the estimates from your model to predict new data points, given values for the model parameters. For this simple example, we just need to know the trial type to make a prediction.
For congruent trials, you would predict that a new data point would be equal to the intercept estimate plus the trial type estimate multiplied by 0.5 (the effect code for congruent trials).
int_est <- my_lm$coefficients[["(Intercept)"]]
tt_est <- my_lm$coefficients[["trial_type.e"]]
tt_code <- trial_types[["congruent"]]
new_congruent_RT <- int_est + tt_est * tt_code
new_congruent_RT## [1] 819.1605You can also use the predict() function to do this more easily. The second argument is a data table with columns for the factors in the model and rows with the values that you want to use for the prediction.
predict(my_lm, newdata = tibble(trial_type.e = 0.5))## 1
## 819.1605
If you look up this function using ?predict, you will see that “The function invokes particular methods which depend on the class of the first argument.” What this means is that predict() works differently depending on whether you’re predicting from the output of lm() or other analysis functions. You can search for help on the lm version with ?predict.lm.
9.4.7 Coding Categorical Variables
In the example above, we used effect coding for trial type. You can also use sum coding, which assigns +1 and -1 to the levels instead of +0.5 and -0.5. More commonly, you might want to use treatment coding, which assigns 0 to one level (usually a baseline or control condition) and 1 to the other level (usually a treatment or experimental condition).
Here we will add sum-coded and treatment-coded versions of trial_type to the dataset using the recode() function.
dat <- dat %>% mutate(
trial_type.sum = recode(trial_type, "congruent" = +1, "incongruent" = -1),
trial_type.tr = recode(trial_type, "congruent" = 1, "incongruent" = 0)
)If you define named vectors with your levels and coding, you can use them with the recode() function if you expand them using !!!.
tt_sum <- c("congruent" = +1,
"incongruent" = -1)
tt_tr <- c("congruent" = 1,
"incongruent" = 0)
dat <- dat %>% mutate(
trial_type.sum = recode(trial_type, !!!tt_sum),
trial_type.tr = recode(trial_type, !!!tt_tr)
)Here are the coefficients for the effect-coded version. They should be the same as those from the last analysis.
lm(RT ~ trial_type.e, data = dat)$coefficients## (Intercept) trial_type.e
## 788.19166 61.93773Here are the coefficients for the sum-coded version. This give the same results as effect coding, except the estimate for the categorical factor will be exactly half as large, as it represents the difference between each trial type and the hypothetical condition of 0 (the overall mean RT), rather than the difference between the two trial types.
lm(RT ~ trial_type.sum, data = dat)$coefficients## (Intercept) trial_type.sum
## 788.19166 30.96887Here are the coefficients for the treatment-coded version. The estimate for the categorical factor will be the same as in the effect-coded version, but the intercept will decrease. It will be equal to the intercept minus the estimate for trial type from the sum-coded version.
lm(RT ~ trial_type.tr, data = dat)$coefficients## (Intercept) trial_type.tr
## 757.22279 61.937739.5 Relationships among tests
9.5.1 T-test
The t-test is just a special, limited example of a general linear model.
t.test(RT ~ trial_type.e, data = dat, var.equal = TRUE)##
## Two Sample t-test
##
## data: RT by trial_type.e
## t = -4.2975, df = 198, p-value = 2.707e-05
## alternative hypothesis: true difference in means between group -0.5 and group 0.5 is not equal to 0
## 95 percent confidence interval:
## -90.35945 -33.51601
## sample estimates:
## mean in group -0.5 mean in group 0.5
## 757.2228 819.1605What happens when you use other codings for trial type in the t-test above? Which coding maps onto the results of the t-test best?
9.5.2 ANOVA
ANOVA is also a special, limited version of the linear model.
my_aov <- aov(RT ~ trial_type.e, data = dat)
summary(my_aov, intercept = TRUE)## Df Sum Sq Mean Sq F value Pr(>F)
## (Intercept) 1 124249219 124249219 11963.12 < 2e-16 ***
## trial_type.e 1 191814 191814 18.47 2.71e-05 ***
## Residuals 198 2056432 10386
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1The easiest way to get parameters out of an analysis is to use the broom::tidy() function. This returns a tidy table that you can extract numbers of interest from. Here, we just want to get the F-value for the effect of trial_type. Compare the square root of this value to the t-value from the t-tests above.
f <- broom::tidy(my_aov)$statistic[1]
sqrt(f)## [1] 4.2974989.6 Understanding ANOVA
We’ll walk through an example of a one-way ANOVA with the following equation:
\(Y_{ij} = \mu + A_i + S(A)_{ij}\)
This means that each data point (\(Y_{ij}\)) is predicted to be the sum of the grand mean (\(\mu\)), plus the effect of factor A (\(A_i\)), plus some residual error (\(S(A)_{ij}\)).
9.6.1 Means, Variability, and Deviation Scores
Let’s create a simple simulation function so you can quickly create a two-sample dataset with specified Ns, means, and SDs.
two_sample <- function(n = 10, m1 = 0, m2 = 0, sd1 = 1, sd2 = 1) {
s1 <- rnorm(n, m1, sd1)
s2 <- rnorm(n, m2, sd2)
data.frame(
Y = c(s1, s2),
grp = rep(c("A", "B"), each = n)
)
}Now we will use two_sample() to create a dataset dat with N=5 per group, means of -2 and +2, and SDs of 1 and 1 (yes, this is an effect size of d = 4).
dat <- two_sample(5, -2, +2, 1, 1)You can calculate how each data point (Y) deviates from the overall sample mean (\(\hat{\mu}\)), which is represented by the horizontal grey line below and the deviations are the vertical grey lines. You can also calculate how different each point is from its group-specific mean (\(\hat{A_i}\)), which are represented by the horizontal coloured lines below and the deviations are the coloured vertical lines.
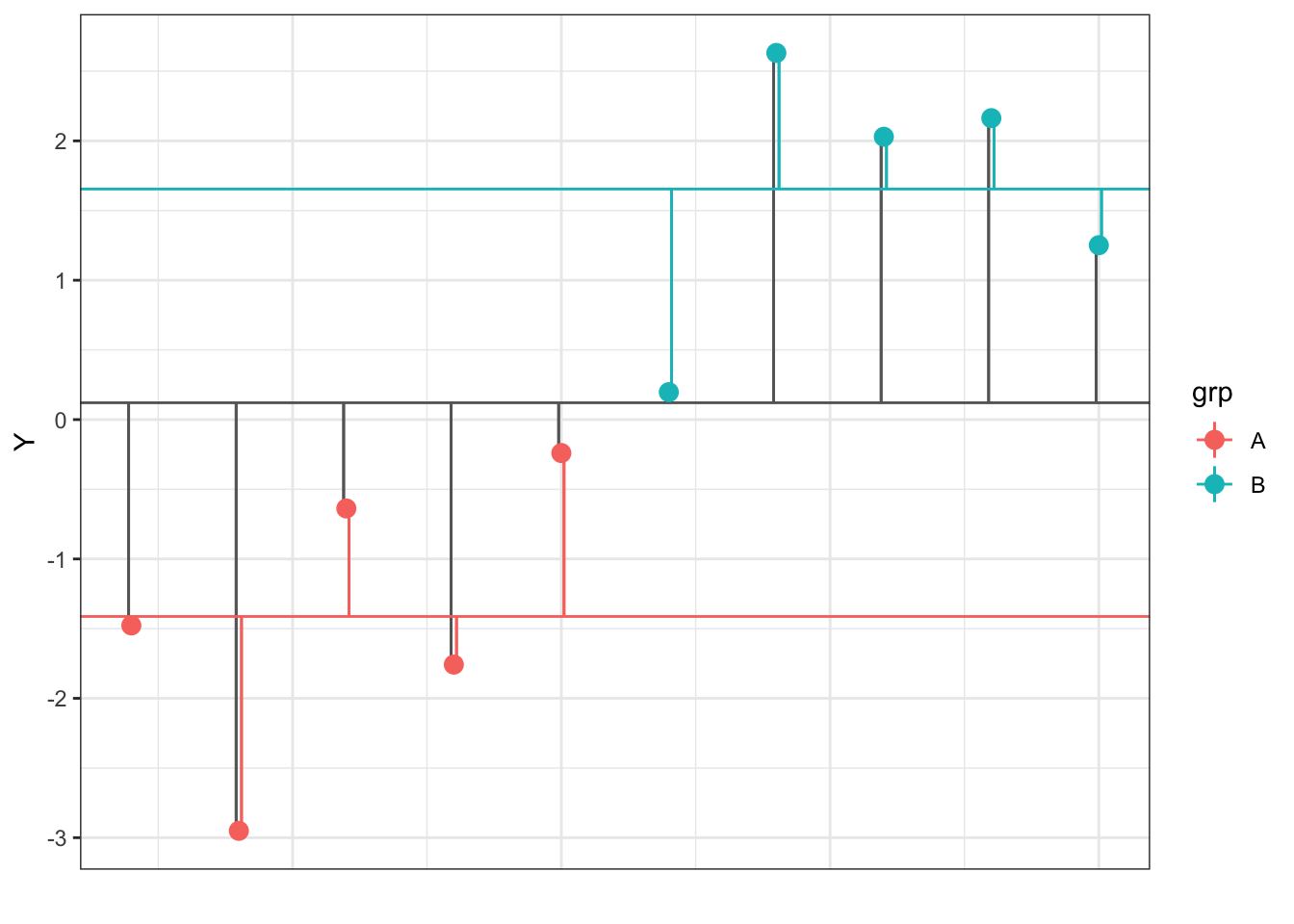
Figure 9.4: Deviations of each data point (Y) from the overall and group means
You can use these deviations to calculate variability between groups and within groups. ANOVA tests whether the variability between groups is larger than that within groups, accounting for the number of groups and observations.
9.6.2 Decomposition matrices
We can use the estimation equations for a one-factor ANOVA to calculate the model components.
muis the overall meanais how different each group mean is from the overall meanerris residual error, calculated by subtractingmuandafromY
This produces a decomposition matrix, a table with columns for Y, mu, a, and err.
decomp <- dat %>%
select(Y, grp) %>%
mutate(mu = mean(Y)) %>% # calculate mu_hat
group_by(grp) %>%
mutate(a = mean(Y) - mu) %>% # calculate a_hat for each grp
ungroup() %>%
mutate(err = Y - mu - a) # calculate residual error| Y | grp | mu | a | err |
|---|---|---|---|---|
| -1.4770938 | A | 0.1207513 | -1.533501 | -0.0643443 |
| -2.9508741 | A | 0.1207513 | -1.533501 | -1.5381246 |
| -0.6376736 | A | 0.1207513 | -1.533501 | 0.7750759 |
| -1.7579084 | A | 0.1207513 | -1.533501 | -0.3451589 |
| -0.2401977 | A | 0.1207513 | -1.533501 | 1.1725518 |
| 0.1968155 | B | 0.1207513 | 1.533501 | -1.4574367 |
| 2.6308008 | B | 0.1207513 | 1.533501 | 0.9765486 |
| 2.0293297 | B | 0.1207513 | 1.533501 | 0.3750775 |
| 2.1629037 | B | 0.1207513 | 1.533501 | 0.5086516 |
| 1.2514112 | B | 0.1207513 | 1.533501 | -0.4028410 |
Calculate sums of squares for mu, a, and err.
SS <- decomp %>%
summarise(mu = sum(mu*mu),
a = sum(a*a),
err = sum(err*err))| mu | a | err |
|---|---|---|
| 0.1458088 | 23.51625 | 8.104182 |
If you’ve done everything right, SS$mu + SS$a + SS$err should equal the sum of squares for Y.
SS_Y <- sum(decomp$Y^2)
all.equal(SS_Y, SS$mu + SS$a + SS$err)## [1] TRUEDivide each sum of squares by its corresponding degrees of freedom (df) to calculate mean squares. The df for mu is 1, the df for factor a is K-1 (K is the number of groups), and the df for err is N - K (N is the number of observations).
K <- n_distinct(dat$grp)
N <- nrow(dat)
df <- c(mu = 1, a = K - 1, err = N - K)
MS <- SS / df| mu | a | err |
|---|---|---|
| 0.1458088 | 23.51625 | 1.013023 |
Then calculate an F-ratio for mu and a by dividing their mean squares by the error term mean square. Get the p-values that correspond to these F-values using the pf() function.
F_mu <- MS$mu / MS$err
F_a <- MS$a / MS$err
p_mu <- pf(F_mu, df1 = df['mu'], df2 = df['err'], lower.tail = FALSE)
p_a <- pf(F_a, df1 = df['a'], df2 = df['err'], lower.tail = FALSE)Put everything into a data frame to display it in the same way as the ANOVA summary function.
my_calcs <- data.frame(
term = c("Intercept", "grp", "Residuals"),
Df = df,
SS = c(SS$mu, SS$a, SS$err),
MS = c(MS$mu, MS$a, MS$err),
F = c(F_mu, F_a, NA),
p = c(p_mu, p_a, NA)
)| term | Df | SS | MS | F | p | |
|---|---|---|---|---|---|---|
| mu | Intercept | 1 | 0.146 | 0.146 | 0.144 | 0.714 |
| a | grp | 1 | 23.516 | 23.516 | 23.214 | 0.001 |
| err | Residuals | 8 | 8.104 | 1.013 | NA | NA |
Now run a one-way ANOVA on your results and compare it to what you obtained in your calculations.
aov(Y ~ grp, data = dat) %>% summary(intercept = TRUE)## Df Sum Sq Mean Sq F value Pr(>F)
## (Intercept) 1 0.146 0.146 0.144 0.71427
## grp 1 23.516 23.516 23.214 0.00132 **
## Residuals 8 8.104 1.013
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Using the code above, write your own function that takes a table of data and returns the ANOVA results table like above.
9.7 Glossary
| term | definition |
|---|---|
| categorical | Data that can only take certain values, such as types of pet. |
| coding scheme | How to represent categorical variables with numbers for use in models |
| continuous | Data that can take on any values between other existing values. |
| dependent variable | The target variable that is being analyzed, whose value is assumed to depend on other variables. |
| effect code | A coding scheme for categorical variables that contrasts each group mean with the mean of all the group means. |
| error term | The term in a model that represents the difference between the actual and predicted values |
| general linear model | A mathematical model comparing how one or more independent variables affect a continuous dependent variable |
| independent variable | A variable whose value is assumed to influence the value of a dependent variable. |
| normal distribution | A symmetric distribution of data where values near the centre are most probable. |
| residual error | That part of an observation that cannot be captured by the statistical model, and thus is assumed to reflect unknown factors. |
| simulation | Generating data from summary parameters |
| standard deviation | A descriptive statistic that measures how spread out data are relative to the mean. |